
Wikisource:Glyphes & caractères/Question
|
|
|


Bienvenue sur la page d’aide à l’identification des glyphes et caractères présent parmi les pages de la Wikisource.
Avant de rédiger votre requête, consulter d'abord la liste des Caractères rares et de leurs usages.
Merci de rédiger clairement votre requête (si possible en indiquant précisément où se trouve le caractère).
AVERTISSEMENT : Wikisource n'offre aucune garantie d'exactitude et décline toute responsabilité en cas d’erreur.
| Ajouter un nouveau message |
Questions[modifier]
Planètes[modifier]
Où peut-on trouver des caractères correspondant aux différentes planètes
- Mercure : Page:Diderot - Encyclopedie 1ere edition tome 10.djvu/370
- Vénus : Page:Diderot - Encyclopedie 1ere edition tome 17.djvu/34
- Mars : Page:Diderot - Encyclopedie 1ere edition tome 10.djvu/149
- Pour Jupiter : Page:Diderot - Encyclopedie 1ere edition tome 9.djvu/64, c'est ♃ (merci Vigneron)
- Pour Saturne : Page:Diderot - Encyclopedie 1ere edition tome 14.djvu/694, Kipmaster a déjà indiqué ♄
- Pour Uranus, Neptune et Pluton, leur découverte est postérieure à la rédaction de l'Encyclopédie.
- Mercure : ☿(l’orientation des "cornes" est légèrement différente selon la police)
- Vénus: ♀
- Terre : ♁ (ou parfois ⊕)
- Mars : ♂
- (pour info, :Jupiter : ♃ ; Saturne : ♄ ; Uranus : ♅ ; Neptune : ♆ ; Pluton : ♇)
- Sinon, pour la question sous-jacente, tu peux essayer de faire une recherche sur une table des caractères (mais le nom est pas toujours intuitif) ou faire une recherche sur Wikipédia (w:Symbole astronomique en l’occurence). Cdlt, VIGNERON * discut. 15 novembre 2010 à 14:13 (UTC)
Verset[modifier]
Les versets sont parfois désignés par un v barré obliquement. cf. Page:Diderot - Encyclopedie 1ere edition tome 10.djvu/47. D'après le wiktionnaire (voir [1]), il existe même un caractère d'imprimerie qu'on désigne sous ce nom, mais je ne le trouve pas. Cordialement, --Acélan (d) 27 novembre 2010 à 09:02 (UTC)
- J'ai trouvé, c'est ℣. Ajouté à la page "collecte". --Acélan (d) 5 décembre 2010 à 17:47 (UTC)
Diverses abréviations[modifier]
Voir ici, à l'article ABRÉVIATION : Page:Diderot - Encyclopedie 1ere edition tome 1.djvu/96 --Acélan (d) 1 décembre 2010 à 08:57 (UTC)
- Je ne pense pas que l’on puisse faire grand’chose pour ces caractères là (au cas où, je vais revoir les dernières version d’Unicode -5 et6- qui ont ajouté pas mal de caractères anciens).
- Sinon, je viens de tomber sur une autre mine : l’article CARACTERE, notamment pp. 651, 652, 653. Là par contre, je sais qu’Unicode possède un grand nombre de ces caractères.
- Cdlt, VIGNERON * discut. 9 décembre 2010 à 10:58 (UTC)
α et ϐ avec un point souscrit[modifier]
Je n'ai pas trouvé comment représenter deux caractères correspondant en grec ancien à 1000 et 2000. Aujourd'hui on les trouve représentés par ͵α et ͵β mais cela ne correspond pas au caractère utilisé dans la page 647 du tome 2 de l'Encyclopédie. Vu que je n'arrive pas à le faire avec l'unicode (U+0323), je l'ai fait avec la proposition de Rical (dite en code/html/css) : α. et ϐ.. Une meilleure idée, chers savants unicodiens ? Piero (d) 18 décembre 2010 à 07:01 (UTC)
- Ouaf, ouaf (ok, je sors).
- Unicode dispose de toutes une flopée de diacritique combinants dont le point souscrit.
- Comme sous-entendu ci-dessus ce caractères se combine à un autre, on peut donc le placer sur ce que l’on veut : ̣α ̣ϐ.
- L’énorme avantage c’est que l’on peut faire un copier-coller, le point reste. Une autre avantage c’est que le code reste simple et lisible. L'inconvénient c’est que le rendu dépend de la police… (chez moi ça passe ; chez vous cela dépend de la police utilisée).
- Cdlt, VIGNERON * discut. 18 décembre 2010 à 18:24 (UTC)
- Je les ai vus et testés, mais dans des solutions trop compliquées. Merci VIGNERON. --Rical (d) 18 décembre 2010 à 18:49 (UTC)
- Ce n'est pas compliqué, les diacritiques standards d'Unicode sont la norme pour ce genre de cas. D'ailleurs le point souscrit diacritique n'est fait que pour ça, même pour les langues latines qui l'utilise (dont le maltais et bon nombre de langues africaines, ou encore la notation API étendue, les notations mathématiques, etc.).
- Donc pas de HTML/CSS pour simuler un point SVP. Ce ne sera jamais portable, et il existe assez de bonnes polices pour afficher les caractères corrects (et il y en aura de plus en plus), alors que le pseudo-code HTML/CSS qui tente de repositionner un point est une véritable horreur (qui ne marche pas non plus selon la taille de police utilisée, ce point étant alors très mal positionné et pas garanti d'être encore en dessous de la ligne, ni même sous la bonne lettre, surtout quand le positionnement est ici indiqué en pixels, au lieu d'être en "em" ou en "ex" !) à ne surtout pas utiliser ! Le point est également trop gros (un point souscrit n'est pas le point de ponctuation). — Verdy_p (d) 10 septembre 2011 à 05:52 (UTC)
- Je les ai vus et testés, mais dans des solutions trop compliquées. Merci VIGNERON. --Rical (d) 18 décembre 2010 à 18:49 (UTC)
mot surligné en html[modifier]
Dans la page encyclopédie 651, en haut de colonne 2, il y a des mots que j'ai surlignés en html parce que je n'ai pas trouvé mieux. Mais vous savez peut-être ? --Rical (d) 18 décembre 2010 à 19:09 (UTC)
- Pour le surlignage par contre, Unicode ne peut pas faire grand’chose.
- Sinon hors du text-decoration, il y a le LaTex (via la balise wiki <math>…</math>.
- Cdlt, VIGNERON * discut. 19 décembre 2010 à 11:06 (UTC)
- Je viens de le faire par LATEX. Merci. --Rical (d) 20 décembre 2010 à 17:05 (UTC)
- Attention le code LaTeX ne permet pas l'adaptation de taille de police. Faites un zoom et regardez l'horreur obtenue lorsque le LaTeX génère une image bitmap !! — Verdy_p (d) 10 septembre 2011 à 05:56 (UTC)
Si on vraiment utiliser Unicode on peut faire:
- Par exemple V̅ signifie 5000 ; L̅X̅, 60000 ; pareillement M̅ est 1000000 ; M̅M̅ est 2000000, &c.
Quelques fontes gèrent ça correctement (le trait doit être lié). Sinon l’HTML ça va. --Moyogo (d) 30 novembre 2013 à 18:25 (UTC)
? ?[modifier]
Quelqu’un aurait une explication pour la présence du caractère ? (touche supprimer !) dans ce texte : [2] ?
Question corolaire : comment repérer ces caractères de contrôles invalides ? (de 0000 à 00&F, 007F à 009F, etc.)
Cdlt, VIGNERON * discut. 19 décembre 2010 à 12:35 (UTC)
- Ça semble être une espace fine insécable U+202F remplacée par la touche supprimer ? U+007F. Elle n’est présente que devant la ponctuation qui devrait être précédé d’une espace fine: deux-points, point-virgule, point d’interrogation, point d’exclamation. --Moyogo (d)
[Al]chimie[modifier]
Si quelqu’un a du temps à perdre, il y aurait la correspondance à faire entre les symboles alchimiques des planches de l’encyclopédie (Page:Encyclopedie Planches volume 2b.djvu/75 et suiv.) et ceux d’Unicode (notamment w:Table des caractères Unicode/U1F700, attention police étendue nécessaire).
Cdlt, VIGNERON * discut. 5 janvier 2011 à 10:43 (UTC)
Quantité[modifier]
Page:Diderot - Encyclopedie 1ere edition tome 13.djvu/499 :
- « Les caracteres de quantité sont trois ; ¯ au-dessus d’une voyelle marque qu’elle est longue ; ˘ signifie qu’elle est brève ; ? indique qu’elle est douteuse » (le point d'interrogation remplace un caractère figuré par un Ω à l'envers).
- --Acélan (d) 6 janvier 2011 à 20:47 (UTC)
- Bizarre, je croyais pourtant me souvenir que ce symbole existait mais je ne retrouve que ℧ (2127, ancien symbole de la w:conductance électrique, donc cela ne correspond pas vraiment au sens recherché).
- Pour information, on retrouve (passim) un symbole très similaire (mais l’oméga inversé devient une diacritique suscrite) dans la Prosodie latine (1871) par A. Le Chevalier.
- Cdlt, VIGNERON * discut. 12 janvier 2011 à 10:05 (UTC)
- Il y en a un autre exemple ici (Page:Diderot - Encyclopedie 1ere edition tome 4.djvu/967), avec une graphie un peu différente (qui ressemble nettement moins à un oméga inversé). --Acélan (d) 17 janvier 2011 à 16:52 (UTC)
- La conductance électrique ℧ est l'inverse de la résistance Ω, d'où le retournement.
- Il y a un lien de forme entre ¯ placé en haut et ˘ placé en bas vers ℧ qui les combine.
- Y-a-t-il une étude des sens grecs des lettres grecques ? Je vais dire un truc fou, mais peut-être sensé. Ω est la fin (de l'alphabet grec) mais l'inverse ℧ n'en est pas le début et représentait peut-être le doute, ou l'intermédiaire, pour les grecs ?
- L'exemple Encyclopédie/967 dit "la quantité étoit à volonté longue ou breve ... par un caractere particulier, semblable à ... cette forme ℧ (écrasé verticalement) que je ne trouve pas dans les 3 groupes unicodes grecs.
- Dans les unicodes grecs il y a un ϖ 03D6, oméga minuscule barré dans la plupart des fontes. --Rical (d) 17 janvier 2011 à 22:19 (UTC)
- malgré la ressemblance avec ω, ϖ est une graphie alternative pour π. --Acélan (d) 19 janvier 2011 à 09:43 (UTC)
- La « ressemblance » n’est pas suffisant (sinon on pourrait échanger les lettres A, Α, et А et faire une recherche ctrl+f serait extrêmement compliqué !) Cdlt, VIGNERON * discut. 21 janvier 2011 à 10:16 (UTC)
- Il y en a un autre exemple ici (Page:Diderot - Encyclopedie 1ere edition tome 4.djvu/967), avec une graphie un peu différente (qui ressemble nettement moins à un oméga inversé). --Acélan (d) 17 janvier 2011 à 16:52 (UTC)
R barré (numismatique)[modifier]
Je viens de trouvé un R barré au niveau de la jambe sur la retranscription d’une pièce (Page:Decombe - Trésor du jardin de la préfecture.djvu/51).
Apparemment, il n’y a rien dans Unicode et je ne trouve rien non plus sur Internet sur la signification de ce glyphe.
Cdlt, VIGNERON * discut. 1 juin 2011 à 19:48 (UTC)
- Je ne vois pas ce caractère sur mon ordi, mais c'est peut être celui que tu cherches : un R barre inscrite (barre oblique), cf Liste de caractères Unicode latins précomposés. Pyb (d) 8 juin 2011 à 08:53 (UTC)
- Propositions : ℞ (recipe) ou ℟ (répons) unicode.org ; mais ça ne ressemble pas exactement à l'un des caractères, au pire mettre simplement R/. Pikinez (d) 9 juin 2011 à 02:33 (UTC)
- A7A6 est très proche de ce que je recherche mais il est indiqué par Unicode comme « Latvian letters for pre-1921 orthography » (donc sémantiquement, très loin de ce que je recherche). De plus, ce caractère a été ajouté dans la version 6 d’Unicode et n’est pour le moment supporté par (apparemment) aucune police d’écriture. Pour le moment, je vais donc me contenter d’un simple R (je ferais peut-être une composition ou bien une image selon mon temps disponible et ma motivation).
- Cdlt, VIGNERON * discut. 12 juin 2011 à 10:56 (UTC)
- D’après moi, le caractère qui convient parfaitement ici est ꝶ U+A776 latin letter small capital rum, mais il est encore rare de trouver ce caractère ajouté dans Unicode 5.1 Emmanuel Vallois (d) 22 septembre 2012 à 03:24 (UTC)
- Propositions : ℞ (recipe) ou ℟ (répons) unicode.org ; mais ça ne ressemble pas exactement à l'un des caractères, au pire mettre simplement R/. Pikinez (d) 9 juin 2011 à 02:33 (UTC)
Glyphe imaginaire[modifier]
Bonjour,
J'ai un problème avec un caractère spécial dans cette page Page:Rosny_-_Les_Xipéhuz,_1888.djvu/47. Vers la fin il est fait usage d'un caractère imaginaire qui semble correspondre à un zéro ayant subi une rotation de 90°. Y a-t-il moyen d'effectuer de telles rotations de 90° avec du texte ? Iggy (d) 2 juin 2011 à 12:57 (UTC)
Copier et mettre l'image du caractère est le mieux je pense, si le caractère « zéro renversé » n'existe pas. Pikinez (d) 2 juin 2011 à 16:32 (UTC)
- En unicode 1D11 est ᴑ (LATIN SMALL LETTER SIDEWAYS O) dans la plupart des polices.
- Mais dans cette version de ebooksgratuits les caractères n'ont pas du tout la même forme, et semblent précisément reproduits. --Rical (d) 2 juin 2011 à 19:11 (UTC)
- Merci pour ces réponses. Je vais voir si le 1D11 a un rendu qui correspond à l'original. Au pire je ferai comme pour les symboles de la page suivante, par extraction du fac similé avec gimp. Par contre, concernant la version de ebooksgratuits, je ne vois pas les glyphes en question : je n'y vois que des zones d'images absentes. --Iggy (d) 3 juin 2011 à 16:49 (UTC)
- Prés du mot "invariablement", Safari et Chrome n'affichent que des images vides, mais Firefox affiche des images en Π "pi majuscule" augmentées de divers détails géométriques. Et les Xipéhuz ont des formes géométriques. Je ne crois pas que l'on puisse parler de lettres, mais plutôt qu'un outil OCR lisant ces formes géométriques les a rendues par des signes. --Rical (d) 3 juin 2011 à 17:29 (UTC)
- Rien à faire je ne vois pas ces glyphes dans ebooksgratuits (Firefox, Chromium ou Midori). Pour mon zéro couché, j'ai fini par utiliser l'image d'un zéro (dans une police sans serif, la plus sobre possible) que j'ai tourné avec gimp. Le rendu me semble correct, à défaut de mieux. --Iggy (d) 7 juin 2011 à 17:58 (UTC)
- Un modèle vient tout juste d’être crée qui répond à ton besoin :
{{rotation}}. Cdlt, VIGNERON * discut. 2 juillet 2011 à 12:16 (UTC)
- Un modèle vient tout juste d’être crée qui répond à ton besoin :
- Rien à faire je ne vois pas ces glyphes dans ebooksgratuits (Firefox, Chromium ou Midori). Pour mon zéro couché, j'ai fini par utiliser l'image d'un zéro (dans une police sans serif, la plus sobre possible) que j'ai tourné avec gimp. Le rendu me semble correct, à défaut de mieux. --Iggy (d) 7 juin 2011 à 17:58 (UTC)
- Prés du mot "invariablement", Safari et Chrome n'affichent que des images vides, mais Firefox affiche des images en Π "pi majuscule" augmentées de divers détails géométriques. Et les Xipéhuz ont des formes géométriques. Je ne crois pas que l'on puisse parler de lettres, mais plutôt qu'un outil OCR lisant ces formes géométriques les a rendues par des signes. --Rical (d) 3 juin 2011 à 17:29 (UTC)
- Merci pour ces réponses. Je vais voir si le 1D11 a un rendu qui correspond à l'original. Au pire je ferai comme pour les symboles de la page suivante, par extraction du fac similé avec gimp. Par contre, concernant la version de ebooksgratuits, je ne vois pas les glyphes en question : je n'y vois que des zones d'images absentes. --Iggy (d) 3 juin 2011 à 16:49 (UTC)
Légion d'honneur[modifier]
Bonjour,
Sur les thèses issus de l’école vétérinaire de Toulouse, on retrouve au début de l’ouvrage une page listant les professeurs. Derrière le nom de certaines de ces personnes, on trouve une étoile indiquant qu’ils sont récipiendaires de la Légion (voire officier). Actuellement, le symbole Unicode utilisé (ici par exemple) est un « flocon de neige » (❄). Outre le fait que sémantiquement, cela ne convient pas. L’étoile de la Légion possède cinq branches et les flocons de neige en possèdent six.
Sans grande conviction, je propose de changer ce caractère par l’« étoile rayonnante » (U+272F, ✯). Quelqu’un aurait une meilleur proposition à faire ?
Cdlt, VIGNERON * discut. 2 juillet 2011 à 12:12 (UTC)
- La Légion d’Honneur est une croix de Malte à 5 branches (five pointed maltese cross). Le standard unicode ne contient que la croix de Malte standard à 4 branches. Je pense que la solution que tu proposes est bonne. Voici la section concernant les étoiles dans le standard unicode : [3]. Zaran (d) 5 août 2011 à 14:39 (UTC)
- Je viens de remarquer qu’Unicode reprend la tradition médiévale selon laquelle une étoile à cinq branches par défaut (comme quoi, le futur n’est jamais bien loin de passé). Du coup, dans le nom des caractères, il n’est jamais précisés à cinq branches (à l’exception de l’étoile à cinq branches arabe ٭ mais qui est rtl dont à éviter). Parmi les différentes étoiles disponibles, l’étoile nautique est probablement le moins mauvais choix. Cdlt, VIGNERON * discut. 8 août 2011 à 22:19 (UTC)
Symbole math. ><[modifier]
Bonjour,
connaissez-vous ce symbole math en forme de nœud papillon >< ici ? Voici le contexte : « Quand un homme A, dans un milieu B, est le siège d’une manifestation quelconque, on n’a jamais le droit de dire rigoureusement : A a fait telle chose. Si l’on veut parler correctement, il faut représenter l’activité observée par la formule symbolique (A >< B), puisque A et B sont indispensables à sa réalisation »
— Pikinez (d) 7 juillet 2011 à 12:18 (UTC)
- D'habitude, je vais chercher sur w:Table des symboles mathématiques. Là je n'ai rien trouvé (à moins que ce ne soit simplement un × ?). Sinon, éventuellement un X (X avec rotation). Cdlt, VIGNERON * discut. 7 juillet 2011 à 13:28 (UTC)
- J'ai décidé de mettre . Merci de ton aide. — Pikinez (d) 10 juillet 2011 à 01:32 (UTC)

- Autre possibilité : U+2AA5 ⪥ GREATER-THAN BESIDE LESS-THAN. --Eric Y Muller (d) 19 juillet 2011 à 00:08 (UTC)
- Comme ça ne s'affiche pas chez moi, je ne l'ai pas mis. Pikinez (d) 19 juillet 2011 à 00:20 (UTC)
- D'après le texte, il ne s'agit pas de comparer 2 valeurs, mais de symboliser une interaction ou une double dépendance.
- On a un problème semblable ici et là et le symbole me semble être vers la fin de la phrase :
- " ou tout simplement "
- ce qui correspondrait à la série de signes unicode
- ⋉ U+22C9 ltimes LEFT NORMAL FACTOR SEMIDIRECT PRODUCT
- ⋊ U+22CA rtimes RIGHT NORMAL FACTOR SEMIDIRECT PRODUCT
- ⋋ U+22CB lthree LEFT SEMIDIRECT PRODUCT
- ⋌ U+22CC rthree RIGHT SEMIDIRECT PRODUCT
- mais où >< n'existe pas. La solution serait donc dans w:LaTeX \times_f , si je me trompe pas. --Rical (d) 19 juillet 2011 à 11:50 (UTC)
- Ne vous donnez pas tant de peine, ça me gêne. Le problème avec les dernières propositions est que cela s'éloigne un peu de l'image du facs. Pikinez (d) 21 juillet 2011 à 02:43 (UTC)
- Il s'agirait de créer un modèle unique qui génère un seul caractère grâce à LaTeX et qui nous permettrait l'accès à tous les symboles mathématiques qui n'existent pas en unicode. Et j'adore ces petits bricolages, voir les modèles Modèle:Rotation Modèle:Auteur. --Rical (d) 22 juillet 2011 à 10:23 (UTC)
- Quand j’aurais le temps, j’écrirais une page d’aide sur comment trouver le bon caractère (et le subtil équilibre entre l’apparence, la signification et les problèmes informatique).
- Bien que ⪥ (2AA5) soit codé depuis Unicode 3 (mars 2002), il semblerait que peu de police l’ai intégré. Sémantiquement, ce symbole est juste la fusion de > et de < (du coup selon la lisibilité de la police on obtient soit deux chevrons soit une croix).
- @Rical : désolé mais tu te trompes : \times_f donne ce qui ne correspond pas du tout au besoin. Quant à ton idée de modèle, je suis plutôt contre : quasiment tout les symboles qui existent en LaTeX existent en Unicode (par contre LaTeX permet de les mettre en forme, typiquement est beaucoup plus difficile à générer en Unicode/html/css qu’en LaTeX). D’ailleurs, selon l’option choisi dans les Spécial:Préférences (dans l’onglet Apparence, section Rendu des maths), l’image issue du code en LaTeX est parfois converti directement en Unicode.
- @Pikinez : sémantiquement et × sont équivalents et désignent tout les deux la multiplication (ou le produit cartésien, ou le produit vectoriel, etc.). Le seul avantage du LaTeX, c’est qu’a priori on limite les problèmes d’affichage. Ceci dit × est codé depuis Unicode 1.1 de 1993 donc les polices qui ne possèdent pas ce caractère doivent être très rare (et peu courante), par contre la tracé du glyphe peut varier.
- Cdlt, VIGNERON * discut. 22 juillet 2011 à 11:38 (UTC)
- Note: ce n'est pas un symbole de mutliplication (qui serait croisé à 90 degrés), mais bien l'accollement (approche négative et ligature) de deux symboles légèrement aplatis.
- Pour moi on peut coder avec :
A <span style="letter-spacing:-.2em">><</span> B - ce qui donne : A >< B
- Cependant en toute rigueur, ce ne sont pas des signes inférieur et supérieur (qui pourrait avoir leur bras inférieur horizontal), mais des pointes de flèche triangulaires, légèrement plus aplaties encore (Unicode a ces deux pointes de flèches ; LaTeX aussi mais pas encore la version intégrée dans la balise Math de MediaWiki). — Verdy_p (d) 18 novembre 2011 à 08:02 (UTC)
- Il s'agirait de créer un modèle unique qui génère un seul caractère grâce à LaTeX et qui nous permettrait l'accès à tous les symboles mathématiques qui n'existent pas en unicode. Et j'adore ces petits bricolages, voir les modèles Modèle:Rotation Modèle:Auteur. --Rical (d) 22 juillet 2011 à 10:23 (UTC)
- Ne vous donnez pas tant de peine, ça me gêne. Le problème avec les dernières propositions est que cela s'éloigne un peu de l'image du facs. Pikinez (d) 21 juillet 2011 à 02:43 (UTC)
- Comme ça ne s'affiche pas chez moi, je ne l'ai pas mis. Pikinez (d) 19 juillet 2011 à 00:20 (UTC)
- Bon, j'allais le faire, mais si ce n'est pas opportun, je laisse. --Rical (d) 23 juillet 2011 à 00:11 (UTC)
- Notez que la doc officielle de LaTeX (qui a toujours été développée sous une licence libre) est maintenant hébergée par Wikimedia sur l'édition anglaise de Wikibooks : C'est sur la partie concernant les mathématiques (voir b:en:LaTeX/Mathematics) que MediaWiki maintient le support de sa balise "math", ainsi que le support de LaTeX vers HTML; cette doc est importante car elle sert de base aussi à MathML, et les deux sont des bases de références pour l'encodage vers Unicode de nouveaux signes mathématiques (et aussi pour les notations phonétiques) ; sur ce wiki on trouve aussi des pointeurs vers différents packages de LaTeX ou les autres dialectes de TeX... — Verdy_p (d) 18 novembre 2011 à 07:51 (UTC)
- Le modèle
{{Caractère|math><}}existe désormais. Il est pour l'instant généré à l'aide des caractères unicode «FULLWIDTH GREATER-THAN SIGN» (> U+FF1E) et «FULLWIDTH LESS-THAN SIGN» (< U+FF1C), qui ont un meilleur rendu que > et < concernant l'angle (> et < donnent une croix trop écrasée par rapport à l'original). Concernant les améliorations qui pourraient être apportées, il est probable que l'ajustement du retrait (.4em) dépende de la police, aussi une image ad hoc serait surement mieux adaptée (ayant aussi l'avantage de constituer un caractère atomique, ce qui peut être important, par exemple si on veut donner plus de chasse avec {{sp}} à ce caractère, ce qui n'est pas possible avec l'implémentation courante où les > et < s'éloigneraient l'un de l'autre). cbonnery (d) 5 février 2012 à 14:26 (UTC)




Symboles très spéciaux[modifier]
Bonjour, je suis actuellement sur le livre Livre:Catalogue Sommaire des Musées de la Ville de Lyon, 1887.djvu où figurent quelques caratères spéciaux et je me demande comment les ajouter voir Page:Catalogue Sommaire des Musées de la Ville de Lyon, 1887.djvu/14 et Page:Catalogue Sommaire des Musées de la Ville de Lyon, 1887.djvu/194 premier paragraphe notamment. Otourly (d) 24 juillet 2011 à 19:15 (UTC)
- Pour la page 14, il s'agit des décorations qu'ils ont : Palmes académiques, légion d'honneur… j'ignore à quelle décoration correspond la Croix de Malte…
- Celui de la page 194 est beaucoup plus rigolo :) - sais-tu ce qu'il est censé symboliser ? --Hsarrazin (d) 24 juillet 2011 à 21:57 (UTC)
- Pour la page 194, serait-ce un signe héraldique ? --Rical (d) 25 juillet 2011 à 11:02 (UTC)
- 194 ressemble à ça Feuille aldine. Pikinez (d) 25 juillet 2011 à 14:18 (UTC)
- oui, effectivement - il ferait donc partie de l'inscription reproduite :) --Hsarrazin (d) 26 juillet 2011 à 09:35 (UTC)
- 194 ressemble à ça Feuille aldine. Pikinez (d) 25 juillet 2011 à 14:18 (UTC)
- Pour la page 194, serait-ce un signe héraldique ? --Rical (d) 25 juillet 2011 à 11:02 (UTC)
- Selon le visualiseur de caractères du Mac :
- ☙ U+2619 Cœur floral couché à droite : n'existe qu'en fonte Apple Symbol et Menlo.
- Existe aussi dans les polices "Code2000" et "Everson Mono" (polices libres et gratuites) — Verdy_p (d) 10 septembre 2011 à 06:17 (UTC)
- ❦ U+2766 Cœur floral : existe en fonte Arial Unicode, Meiryo, Menlo, Minion Pro, MS Gothic, MS, Zapf.
- ❧ U+2767 Cœur floral couché : existe dans les 7 mêmes fontes.
- Le plus simple à utiliser, est en bonne position ☙ U+2619 et on peut le dilater ☙.
- Les plus disponibles en nombre de fontes sont ❦ U+2766 et ❧ U+2767.
- On peut les tourner par le modèle
{{Rotation}}et les dilater : 2766 = ❦ et 2767 = ❧, mais leur pointe tourne du mauvais coté. - Sur Mac OSX 10.6.8, je vois les 3 dans Firefox, Safari, Google Chrome et Opéra, et vous ?
- Lequel choisir ? --Rical (d) 26 juillet 2011 à 14:23 (UTC)
- Moi je vois les trois mais je possède des polices qui me permettent de voir quasiment tout l’Unicode donc je ne suis pas vraiment une référence. Personnellement, j’aurais tendance à utiliser ☙ qui correspond directement à ce qui est recherché. La question que je me pose est : y a-t-il plus de personnes qui ne possède pas la police permettant de visualiser ce caractère ou bien y a-t-il plus de personnes utilisant un navigateur où le modèle
{{rotation}}ne fonctionne pas. - Pour la légion d’honneur, on retombe sur ma question ci-dessus. Pour les palmes académiques, je n’ai encore rien trouvé de mieux que ⸙ (2E19) mais pour la croix (une croix de guerre ?), une croix de Malte pourrait convenir : ✠ (2720).
- Du coup, je me dit que insérer une image serait probablement ce qu’il y a de mieux (et peut-être via un modèle pour simplifier la mise à jour si Unicode ajoute ces caractères).
- Cdlt, VIGNERON * discut. 5 août 2011 à 11:42 (UTC)
- Il y a bien une solution, c'est d'utiliser les "webfonts" (déclaration d'une police dans CSS avec @font, dont les glyphes sont définissables par une police facile à créer au format SVG, qu'on pourrait enrichir avec nos besoins). Les polices SVG commencent à être bien supportées par les navigateurs, il n'y pas que les polices TrueType ou OpenType (plus complexes et nécessitant des outils chers, même si elles ne sont pas capables encore de gérer les écritures complexes nécessitant des ligatures et formes contextuelles ou variantes différentes pour le même caractère Unicode).
- Je suis d'avis qu'on pourrait créer notre propre police SVG servie par une telle Webfont définie dans notre feuille de style CSS, afin de supporter les caractères rares à commencer par les symboles. Cela marcherait même pour les caracères non encore encodés dans Unicode mais qu'on peut assigner à un code PUA, assigné dans notre police Webfont... Dessiner un glyphe manquant en SVG n'est pas compliqué, on a des tas d'outils pour le faire dans un graphique vectoriel SVG, d'où on extrait alors juste le "path" à inclure dans la police SVG. Le format des polices SVG est assez simple et ne nécessite aucun compilateur, juste un éditeur de texte.
- Note: Google utilise les Webfonts dans GoogleDocs, même si les glyphes eux-mêmes sont compilés dans une police OpenType libre, et fournit aussi une API simplifiant l'emploi de ces polices dans n'importe quel site avec un javascript minuscule (mais pas obligatoire si on peut écrire le code CSS soit-même pour "@font"). — Verdy_p (d) 10 septembre 2011 à 06:13 (UTC)
- Cette solution m’intéresse et je pense depuis un certain temps à créer une police spécifique (mais l’ampleur et la complexité de la tache m’ont jusque là interdit de le faire tout seul). Par contre, je n’aime pas du tout le « Les polices SVG commencent à être bien supportées par les navigateurs ». Cela veut dire que seul les navigateurs les plus modernes pourront avoir la bonne police ?
- Le format OpenType a atteint ses limites, même s'il a été normalisé depuis par l'ISO. Les polices SVG commencent à être populaires, mais leur spécification ne comporte pas encore le support des règles de substitution et positionnement contextuel des glyphes (ce qui le rend encore inutilisable pour autre chose que le chinois, le japonais et le coréen moderne, et est déjà insuffisant pour ne serait-ce que pour supporter complètement les écritures gréco-latines, et encore incompatible pour les écritures complexes comme l'arabe, l'hébreu et toutes les écritures brahmiques. Ce format SVG est pourtant bien plus facilement extensible que le format OpenType (qui possède par ailleurs des tas d'antiquités héritées, source déjà de nombreuses incompatibilités ou ambiguïtés). C'est d'ailleurs en raison de ses insuffisances que sont nées les extensions (incompatibles entre elles) comme celles d'Apple (AAT), Microsoft (pour Uniscribe), d'Adobe (pour ActiveScript et Flash), et de SIL (Graphite). On sent bien qu'il faut un format facile à décoder et ne reprenant que le meilleur des technologies (et en abandonnant le "font hinting" qui n'est presque plus nécessaire, et qui complique tout pour plus grand chose sur nos écrans et imprimantes actuels qui commencent à atteindre les 200 dpi, et qui ont des géométries de pixels et des systèmes colorimétriques et de transparence incompatibles avec le font-hinting d'OpenType ou ClearType ; les améliorations sensibles sont dans le rendu photographique et sensoriel, et vont vers des technologies anisotropes et non plus des "grilles" de pixels restangulaire avec leurs effets de moiré très indésirables; on va vers des rendus multicouches avec des grilles superposées et non plus entrelacées comme maintenant). — Verdy_p (d) 18 novembre 2011 à 07:46 (UTC)
- Sans lien direct mais pour mémoire, la Wikimedia Foundation est désormais membre de liaison officiel du Consortium Unicode (depuis le 18 juillet).
- Cdlt, VIGNERON * discut. 11 septembre 2011 à 18:32 (UTC)
- Ca tombe, bien, j'en suis membre aussi... Ce qui me permet de voir tout ce qui nous attend dans les versions en préparation, et aussi de voir le calendrier des discussions, commenter les propositions de codage, corrections, bien avant même la publication (souvent urgente) des versions beta pendant souvent à peine un mois (et difficile de faire des corrections au moment des betas Unicode, sauf au plan purement éditorial ou les erreurs réellement flagrantes, car les décisions sont déjà toutes passées).... — Verdy_p (d) 18 novembre 2011 à 07:34 (UTC)
- Cette solution m’intéresse et je pense depuis un certain temps à créer une police spécifique (mais l’ampleur et la complexité de la tache m’ont jusque là interdit de le faire tout seul). Par contre, je n’aime pas du tout le « Les polices SVG commencent à être bien supportées par les navigateurs ». Cela veut dire que seul les navigateurs les plus modernes pourront avoir la bonne police ?
- Moi je vois les trois mais je possède des polices qui me permettent de voir quasiment tout l’Unicode donc je ne suis pas vraiment une référence. Personnellement, j’aurais tendance à utiliser ☙ qui correspond directement à ce qui est recherché. La question que je me pose est : y a-t-il plus de personnes qui ne possède pas la police permettant de visualiser ce caractère ou bien y a-t-il plus de personnes utilisant un navigateur où le modèle
Scansion[modifier]
Bonjour,
Je soumets la page Page:Mommsen - Histoire romaine - Tome 1.djvu/321 sur laquelle Marc, Pmx et Zyephyrus viennent d’apporter des améliorations. Qu’en pensez-vous ? Est-ce une bonne pratique à reproduire ? N’y a-t-il pas une diacritique combinant en Unicode qui conviendrait mieux (j’avoue avoir cherché sans succès).
Cdlt, VIGNERON * discut. 24 septembre 2011 à 18:04 (UTC)
- Si si! Il existe des demi-signes diacritiques (à poser sur la première et sur la dernière lettre d'une liaison), ainsi qu'un signe de prolongation horizontal (à placer sur les lettres médianes). Consulte http://www.unicode.org/charts/PDF/UFE20.pdf
- Donc U+FE20 (COMBINING LIGATURE LEFT HALF) codé juste après la première lettre, U+FE26 (COMBINING CONJOINING MACRON) après chacune des lettres intermédiaires, U+FE21 (COMBINING LIGATURE RIGHT HALF) après la dernière lettre...
- Si on n'a que deux lettres, ne pas utiliser ces demi-signes mais directement un signe "double largeur" entre les deux lettres (ici U+0361 pour une liaison de deux lettres sous la forme d'une longue brève arrondie, inversée).
- On peut faire la même chose aussi pour étendre les signes macrons (utiliser les demi-macrons droite et gauche avec le macron jointif U+FE26), et pour étendre les tildes (utiliser les demi-tildes avec aussi le macron jointif).
- En revanche, pas encore pour de demi-signes pour étendre un signe de liaison arrondi inférieur à plus de deux lettres, mais ils vont être ajoutés d'ici peu dans Unicode 6.1. — Verdy_p (d) 18 novembre 2011 à 03:58 (UTC)
- Voir Modèle:Multiligature pour la doc et la façon dont c'est résolu... J'ai essayé différents compromis, cela marche correctement à condition que le texte soit en zoom 100% et pour une taille de police de texte standard, sinon le trait de bordure supérieur au dessus des lettres médianes n'est plus jointif. — Verdy_p (d) 18 novembre 2011 à 05:51 (UTC)
- J’ai remis la version précédente, parce que des petits traits bizarrement disposés n’évoquent pas vraiment ce qui est à reproduire. La solution actuelle n’est pas belle et est aussi assez mal faite, mais on reconnaît au moins la forme. Marc (d) 18 novembre 2011 à 09:35 (UTC)
- Si tu n'es toujours pas convaincu que c'est la façon de faire: http://std.dkuug.dk/JTC1/SC2/WG2/docs/n4078.pdf
- Note que pour l'instant le macron long central jointif est encore codé avec une bordure, en attendant un meilleur support de U+FE26. Mais Unicode a déjà décidé de supporter les diacritiques triples suscrits de cette façon, et va continuer avec des diacritiques triples souscrits (macron souscrit, tilde souscrit, et brève souscrite)... La raison d'être du modèle est de faciliter l'écriture pour ne pas avoir à taper une syntaxe lourde dans le texte.
- Les polices utilisant les caractères U+FE2x existent déjà. Désolé mais c'est bien la façon de faire, et « ça ressemble à quelquechose ». — Verdy_p (d) 24 novembre 2011 à 15:22 (UTC)
Un modèle pour caractères spéciaux[modifier]
Pour les caractères que nous ne trouvons pas en unicode, nous pourrions créer un modèle :
- qui regroupe tous ces caractères et permet de les repérer partout ;
- qui donne à chacun un nom nouveau, qui ne correspond à aucun caractère existant ;
- qui utilise n'importe quelle technique pour y arriver (Latex, combinaison et décalage de caractères, fichier.svg, image ...)
- ce qui suppose à chaque fois un débat sur le nom et la technique, et les conséquences dans diverses conditions d'utilisations (navigateur, jeu de caractères ...) mais c'est inhérent au problème.
Qu'en pensez-vous ? --Rical (d) 30 janvier 2012 à 23:35 (UTC)
- Excellent !
- pour le listage, cela risque de ce faire au fur et à mesure des « découvertes ».
- cela sera peut-être délicat dans certain cas mais globalement, cela ne devrait pas être trop dur.
- je pensais uniquement à une image (au format SVG de préférence mais sans contrainte). Je ne vois pas comment utiliser le LaTeX mais je connais finalement assez mal ce langage. Je ne vois pas non plus trop dans quel cas utiliser la technique de « combinaison et décalage » mais j’imagine que cela doit arriver.
- oui évidemment. Ces débats permettront de répondre aux questions précédentes ;)
- J’en pense beaucoup de bien ! Ce modèle pourra être très utile.
- De plus, soit via les spécial:Pages liées, soit via des catégories cachées cela permettra de suivre l’utilisation de ces caractères (choses que l’on ne fait pas du tout pour le moment), donc de pouvoir apporter des données précises au consortium Unicode pour un éventuel ajout dudit caractère dans la norme Unicode. Cdlt, VIGNERON * discut. 31 janvier 2012 à 08:28 (UTC)
- Je veux bien créer le Modèle:Caractère avec 2 caractères et technos différentes, ce nom ne semble pas du tout utilisé pour les modèles.
- Usage : {{Caractère|WS Légion d'Honneur}}. Il pourrait y avoir des options de taille ?
- La technique de « combinaison et décalage » est utilisée dans Modèle:PointSouscrit.
- Mais je ne vais pas être rapide, 2 semaines très chargées personnellement m'attendent. --Rical (d) 31 janvier 2012 à 10:06 (UTC)
- Caractère me semble bien comme nom. Pour la techno, je te fais confiance pour faire au mieux et au plus simple.
- Pour l’usage :
{{Caractère|Légion d'Honneur}}suffit, non ? Ce serait plus propre de nommé le paramètre ({{Caractère|caractère=Légion d'Honneur}}) mais cela va compliqué l’utilisation. Un paramètre pour la taille serait un avantage appréciable. - J’avais oublié
{{PointSouscrit}}(désolé). Dans le genre, il y a aussi{{rotation}}qui accomplit très bien son travail. Cela doit-il être intégré dans ce modèle ou par des modèles particuliers ? Surtout que − même si c’est compliqué − Unicode est souvent capable de gérer ce genre de cas. J’aimerais réserver ce modèle au cas où l’on peut vraiment que difficilement faire autrement : soit le caractère n’existe pas en Unicode, soit éventuellement si le caractère est absent des polices (cas temporaire a priori). Et donc, je peux me tromper mais les décalages me semblent plutôt à exclure de ce modèle. En outre, je ne vois pas bien comment cela va fonctionner, on aura un nom de caractère pour chacune des lettres avec un point souscrit ? (rien que les lettres des alphabets grecques et latins, cela fait plusieurs centaines de caractères ; si l’on prend en compte d’autres diacritiques, cela fait rapidement des milliers de caractères à gérer !) - Inutile de se presser, on peut attendre deux semaines ; au contraire j’aimerais bien avoir d’autres avis avant.
- Ce serait pas mal de recenser les caractères à intégrer dans ce modèle. Je commence :
- légion d’honneur,
- palmes académique,
- le #R barré (numismatique) (mais il faudrait creuser un peu la question pour trouver le nom et l’usage exact ; surtout qu’il existe déjà plusieurs R barré différents dans Unicode ; celui-ci semble vouloir abréger le monogramme RX pour Rex),
- le #Symbole math. >< (le décalge me semble suffisant non ?)
- ?
- Cdlt, VIGNERON * discut. 31 janvier 2012 à 11:08 (UTC)
- Pour moi et pour l'instant, le code de base est très simple :
- if param1="légion d’honneur" then "insérer le fichier légion-d’honneur.svg comme un caractère"
- if param1="math><" then >< (par Pointsous)
- if param1="palmepenchée" then W (par Rotation)
- Un if pour chaque caractère à coder. Reste à ajuster chaque code dans chaque cas.
- Dans le code de base chacun met des exemples de ce qu'il arrive à faire, pour transmettre ce savoir faire. Et la doc pointe sur les modèles liés.
- La doc sera bien plus longue, avec une brève justification du codage choisi pour chaque caractère, avec tous les conseils, tous les tests minimum à réaliser dans tous les cas (navigateurs, HTML4, HTML5 ...). --Rical (d) 31 janvier 2012 à 21:52 (UTC)
- Ok, j’imaginais un truc comme cela (avec #switch plutôt que des #if et avec quelques paramètres pour le rendu, eg. : {{caractère|palmes académiques|angle=180|taille=2em}}).
- Par contre, je crois savoir qu’il y a une limite au nombre de if/switch utilisable dans un modèle et je crains que l’on ne l’a dépasse. C’est pourquoi je voulais me concentrer sur ce qui ne pouvais pas se faire autrement (typiquement les images), après je me trompe peut-être et si tu arrives à faire, n’hésites surtout pas ! Cdlt, VIGNERON * discut. 1 février 2012 à 11:51 (UTC)
- Pour moi et pour l'instant, le code de base est très simple :
- Exemples de Modèle:Caractère :
 ,
, 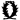 , R_,
, R_,  , ,
, ,  , ⍰, W., ⍰, ⍰, ⍰, ⍰, --Rical (d) 1 février 2012 à 23:16 (UTC)
, ⍰, W., ⍰, ⍰, ⍰, ⍰, --Rical (d) 1 février 2012 à 23:16 (UTC)

Modèle pour caractères spéciaux[modifier]
- Dans ma page de discussion, Utilisateur:Acélan me signale le modèle {{?}} = ? = Modèle:Symbole manquant que je ne connaissais pas. Et demande comment utiliser le Modèle:Caractère ? Et je découvre maintenant la Catégorie:Mots manquants.
- Finalement Modèle:Caractère prolonge Modèle:Symbole manquant en codant des caractères, et tout ce qui suit est à discuter ...
- * Le Modèle:Caractère génére des caractères et en contient une liste. S'il y en a trop pour un seul modèle on peut créer des modèles frères. Par exemple séparer "inconnu" et "spécial".
- * Les pages contenant les caractères déjà validés par les spécialistes apparaissent dans la Catégorie:Caractère spécial. Les pages contenant les caractères en cours de recherche ou en test de compatibilité apparaissent dans la Catégorie:Caractère inconnu équivalente à Catégorie:Mots manquants.
- * Mots, symboles ou caractères ? Signaler ou générer ou les deux ?
- * Pour le modèle {{?}} = Modèle:Symbole manquant, on peut le garder tel quel, il collecte déjà des cas difficiles.
- * On peut aussi fusionner les 2 modèles pour les langues.
- * Le nom "?" est court mais ambigu. "Symbole manquant" est expressif mais long. On pourrait utiliser "Car" pour raccourcir "Caractère". On pourrait rediriger "?", "Car" et "Symbole manquant" vers "Caractère" ?
- * On peut accumuler du savoir-faire de codages en commentaire, à la fin du code source du modèle.
- * Hors sujet, mais pratique : Dans mes préférences j'ai activé le gadget Popups qui permet de voir les contenus de pages au survol de leur lien par la souris. Et cela permet même de voir les contenus de Catégorie:Caractère spécial et de Catégorie:Caractère inconnu alors que ces pages n'existent pas ! C'est magique. --Rical (d) 18 février 2012 à 00:12 (UTC)
- J'ai encore un peu avancé, créé la Catégorie:Caractère spécial et utilisé quelques caractères dans des pages.
- Pour le
{{Caractère|X horizontal}}→ , il y a une erreur dans le nom du fichier qui contient un "n" après "ho".
qui contient un "n" après "ho". - Mais il reste un mystère : La taille de math>< n'est pas modifiable. Faut-il passer par "Point Souscrit" ou par fichier ?
- Pour l'instant, il me semble que ce modèle peut commencer à servir ? --Rical (d) 20 février 2012 à 01:11 (UTC)
- Modèle:Caractère est de la pâte à modeler, à adapter en permanence à de nouveaux caractères ou de nouvelles graphies.
- Il faut essayer de rester aussi transparent que possible à tous les niveaux, des Utilisations avancées à la Documentation de codage en fin du modèle. Le signaler dans l'aide.
- {{?}} = ? est déjà une redirection de Modèle:Symbole manquant. On peut le rediriger vers Modèle:Caractère s'il le remplace sans erreur.
- Une série de tests et de caractères à repérer devrait vous occuper un moment !
- Apprivoisez-le, je surveille, s'il a besoin de se faire opérer appelez-moi. Une appli sur iPhone m'attend. --Rical (d) 20 février 2012 à 12:18 (UTC)
- Pour que les caractères spéciaux ne soient pas sur fond toujours blanc j'ai créé une série de caractères SVG.
- Mais je ne sais pas comment faire pour qu"ils changent de couleurs comme de vrais caractères. Est-ce possible avec Inkskape ? Je n'ai pas trouvé comment.
- Pour qu'ils soient disponibles dans tous les wikis, je les ai mis dans commons dans Category:Glyphs in SVG
- Et je les ai inclus dans le modèle. --Rical (d) 28 février 2012 à 21:08 (UTC)
Un caractère à identifier[modifier]
C'est ici : Page:Guy - Du perchlorure de fer.djvu/15, et sur toutes les pages de l'ouvrage marquées "non corrigées". --Acélan (d) 5 février 2012 à 22:51 (UTC)
- Phe me répond : "Je crois qu'il s'agit de ♃ ou
 , bien que je vois pas trop le rapport avec du perchlorure de fer ("Etain dominé par Jupiter" en alchimie) — Phe 5 février 2012 à 23:07 (UTC)" ;
, bien que je vois pas trop le rapport avec du perchlorure de fer ("Etain dominé par Jupiter" en alchimie) — Phe 5 février 2012 à 23:07 (UTC)" ; - vu l'usage qui est fait de ce symbole en pharmacologie, ça doit être ça, en effet (cf. page de collecte, et exemple dans l'Encyclopédie). --Acélan (d) 6 février 2012 à 06:01 (UTC)
- ♃ convient bien mais c’est un symbole astrologique/astronomique pour Jupiter. Depuis sa version 6.0 Unicode sortie en octobre 2010 possède certains symboles alchimiques (listés ici : w:Table des caractères Unicode/U1F700). On y trouve notamment 🜩 (U+1F729) qui visuellement convient aussi (bien que moins présents dans les polices courantes) ALCHEMICAL SYMBOL FOR TIN ORE. Donc effectivement, on est sur l’étain et non sur le fer, bizarre mais pas inhabituel.
- Cdlt, VIGNERON * discut. 10 février 2012 à 09:24 (UTC)
Trévouserie hébraïque[modifier]
Bonjour à tous, les wikisorciers, sur cette page, j'ai une difficulté typographique avec 1 mot hébreu dont chaque lettre est à l'envers (la tête en bas) et le mot aussi (il commence par la fin). J'ai mis ce qui est correct (il s'agit du mot qui correspond à arith, en fin de page), mais comment indiquer l'erreur ? Usage de m:rotate ? --Acer11 (d) 5 mars 2012 à 12:01 (UTC)
- Bonjour Acer,
- à ta place, je me contenterais de le mettre en
{{corr}}, avec une explication en PdDiscussion… le prote a sans doute "retourné" le mot, sans s'en rendre compte, puisque même si ces braves gens savaient lire (une exception à l'époque), la plupart ne devaient pas comprendre l'hébreu ;) - si tu tiens à reproduire l’erreur du prote, tu peux peut-être essayer avec le modèle{{rotation}}avec un angle de 180° (sans garantie, je ne l'ai jamais utilisé), mais est-ce bien nécessaire ? ;) --Hélène (d) 6 mars 2012 à 07:48 (UTC)- Tout comme hélène :
{{rotation}}peut répondre à ton besoin mais as-tu vraiment ce besoin ? Perso, j’utiliserais{{corr}}. Cdlt, VIGNERON * discut. 16 mars 2012 à 12:33 (UTC)- Ouuups j'avais négligé de vous remercier ! C'est vrai qu'il ne s'impose pas de reproduire les aberrations typo. Un peu d'excès dans le souci de reproduire « à l'identique ».... merci donc. --Acer11 (d) 29 mars 2012 à 06:07 (UTC)
- Vu tout le travail que tu fais, en toute discrétion, et continûment, pour améliorer le script du Trévoux (qui "est" un vrai luxe, mais "pas du tout" superflu, pour répondre à une de tes récentes questions), et pour lequel nous ne pensons jamais à te dire un gros Merci
 , on ne t'en veux pas vraiment :) --Hélène (d) 29 mars 2012 à 11:54 (UTC)
, on ne t'en veux pas vraiment :) --Hélène (d) 29 mars 2012 à 11:54 (UTC)
- Vu tout le travail que tu fais, en toute discrétion, et continûment, pour améliorer le script du Trévoux (qui "est" un vrai luxe, mais "pas du tout" superflu, pour répondre à une de tes récentes questions), et pour lequel nous ne pensons jamais à te dire un gros Merci
- Ouuups j'avais négligé de vous remercier ! C'est vrai qu'il ne s'impose pas de reproduire les aberrations typo. Un peu d'excès dans le souci de reproduire « à l'identique ».... merci donc. --Acer11 (d) 29 mars 2012 à 06:07 (UTC)
- Tout comme hélène :
t dans le c (ligature)[modifier]
Bonjour, je n'arrive pas à trouver le ct lié (comme le st en st). On peut le trouver là, p. 142, avant-dernier paragraphe… Totodu74 (d) 27 mars 2012 à 17:34 (UTC)
- Bonjour, habituellement, sur Wikisource (voir Aide:Guide typographique) on ne reproduit pas les ligatures, car cela complique la recherche dans le texte :) --Hélène (d) 27 mars 2012 à 18:08 (UTC)
- C'est vrai que c'est pas faux, mais en fait c'était pour faire une citation sur… Wikipédia Totodu74 (d) 27 mars 2012 à 18:12 (UTC)
- En fait, je crois qu'il faut utiliser w:Linux libertine pour les ligatures, en particulier le "ct" qui est une ligature purement "esthétique" [4] :) - bon courage --Hélène (d) 27 mars 2012 à 18:34 (UTC)
- Hum, c'est compliqué. Bon je crois que je l'ai quand même trouvé (via une recherche Google images), c'est
(« »). Le problème c'est qu'il ne s'affiche pas chez moi, et j'imagine, chez pas mal d'autres gens. Totodu74 (d) 27 mars 2012 à 19:09 (UTC)- d'après ce que j'ai pu lire, c'est pour ça qu'il faut utiliser "Linux Libertine"… ce caractère n'existe que dans très peu de polices :) - par contre, je crois qu'il y a un projet en cours, qui devrait permettre à tout le monde d'afficher les caractères y compris de polices qu'on n'a pas sur sa machine [[5]] - je ne sais pas s'il est installé sur Wikipedia… il faudrait soumettre le projet --Hélène (d) 27 mars 2012 à 19:12 (UTC)
- Ah ça me dit quelque chose, et oui ce serait une très bonne chose. Pour LinuxLibertine, le truc c'est que si je sais afficher la police, je ne sais pas comment ajouter les ligatures historiques (un hlig=1 quelque part si j'ai bien compris…) Totodu74 (d) 27 mars 2012 à 19:20 (UTC)
- sur WS, tu peux utiliser le modèle
{{ligat}}… mais je ne pense pas qu'il fonctionne sur WP… à tester… :-)--Hélène (d) 27 mars 2012 à 19:23 (UTC)- Sur WP il n'existe pas et sur WS… il faut modifier son css pour voir la ligature, c'est bien ça (ou elle est bien là et je suis bigleu
 ) ? Totodu74 (d) 27 mars 2012 à 19:30 (UTC)
) ? Totodu74 (d) 27 mars 2012 à 19:30 (UTC)
- je pense qu'il faut modfier son CSS (ou celui du texte sur lequel on travaille) - mais je ne suis pas experte des ligatures ;) --Hélène (d) 27 mars 2012 à 20:33 (UTC)
- Ok, mais bon je saurais pas modifier le common.css et surtout ce ne serait peut-être pas une bonne idée de changer la police d'écriture au milieu d'une phrase. Je vais me contenter du ct, sans les fioritures d'antan Merci pour ton aide ! Totodu74 (d) 28 mars 2012 à 12:27 (UTC)
- Ok, mais bon je saurais pas modifier le common.css et surtout ce ne serait peut-être pas une bonne idée de changer la police d'écriture au milieu d'une phrase. Je vais me contenter du ct, sans les fioritures d'antan
- je pense qu'il faut modfier son CSS (ou celui du texte sur lequel on travaille) - mais je ne suis pas experte des ligatures ;) --Hélène (d) 27 mars 2012 à 20:33 (UTC)
- Sur WP il n'existe pas et sur WS… il faut modifier son css pour voir la ligature, c'est bien ça (ou elle est bien là et je suis bigleu
- sur WS, tu peux utiliser le modèle
- Ah ça me dit quelque chose, et oui ce serait une très bonne chose. Pour LinuxLibertine, le truc c'est que si je sais afficher la police, je ne sais pas comment ajouter les ligatures historiques (un hlig=1 quelque part si j'ai bien compris…) Totodu74 (d) 27 mars 2012 à 19:20 (UTC)
- d'après ce que j'ai pu lire, c'est pour ça qu'il faut utiliser "Linux Libertine"… ce caractère n'existe que dans très peu de polices :) - par contre, je crois qu'il y a un projet en cours, qui devrait permettre à tout le monde d'afficher les caractères y compris de polices qu'on n'a pas sur sa machine [[5]] - je ne sais pas s'il est installé sur Wikipedia… il faudrait soumettre le projet --Hélène (d) 27 mars 2012 à 19:12 (UTC)
- Hum, c'est compliqué. Bon je crois que je l'ai quand même trouvé (via une recherche Google images), c'est
- En fait, je crois qu'il faut utiliser w:Linux libertine pour les ligatures, en particulier le "ct" qui est une ligature purement "esthétique" [4] :) - bon courage --Hélène (d) 27 mars 2012 à 18:34 (UTC)
ƈt ? et deux caractères je sais c'est tricher :p Otourly (d) 28 mars 2012 à 16:02 (UTC)
- Mais c'est bien joué ! (j'ai juste pris aƈte de ta réponse, je ne vais pas insérer ce caraƈtère bizarre dans le texte) Totodu74 (d) 28 mars 2012 à 17:02 (UTC)
Oula, j’arrive après la bataille dommage j’ai plein de choses à dire :
- Alors, mis à part pour les ligatures orthographiques (œ et æ pour la langue française, ß en allemand, etc.), il ne faut jamais « forcer » les ligatures esthétiques dans du texte. Les caractères unicodes comme ff, fi, fl, ffi, ffl, ſt, st sont à bannir définitivement (Unicode le dit lui-même, ces caractères ne sont là que pour des raisons techniques/historiques de rétro-compatibilité).
- Par contre, il existe plusieurs autres solutions. Par exemple, Unicode a tout de même prévu une technique : le liant sans chasse (celui utilisé par le modèle
{{ligat}}). Ceci dit, le rendu effectif de ces solutions dépend de nombreux paramètres (navigateur, système et police présentes sur le système du lecteur). Personnellement, j’ai abandonné l’affaire temporairement et j’attends que les navigateurs s’améliorent et surtout se mettent d’accord sur la façon de gérer la chose.
PS: Otourly, c’est quoi ce gros hack unicodesque ? C’est effectivement joli (sur mon ordi, j’ai bien peur que ce soit instable pour le lecteur) mais totalement à proscrire pour le français (en plus, sur le plan technique, pourquoi avoir utiliser deux liants sans chasses : « ƈt » au lieu de « ƈt » ; chez moi je ne vois pas de différence :P). Cdlt, VIGNERON * discut. 29 mars 2012 à 08:18 (UTC)
- T'inquiètes, j'ai laissé tomber le truc, mais tant qu'à utiliser les vieilleries d'antan (je pense au s long), je me disais que s'il était possible d'aller jusqu'au bout… :) Merci pour tes explications, Totodu74 (d) 30 mars 2012 à 11:59 (UTC)
Aides aux langue anciennes[modifier]
Je n'ai aucune notion en langues anciennes (hormis un peu de latin) et j'hésite sur la conduite à tenir pour ce type de pages : pour la retranscription de l'image j'ai posé la question dans une autre partie de l'aide, mais pour demander de l'aide ou signifier qu'il y a une partie du texte dont je ne connais pas la langue ou l'alphabet, quelle procédure suivre pour la porter à l'attention de quelqu'un qui s'y connaitrait un peu mieux ?
- Tu peux mettre
{{?}}, en précisant la langue en paramètre (voir mode d'emploi en cliquant sur le nom du modèle}} :) - si tu ne connais pas le nom de l'alphabet, précise "alphabet inconnu" - en l'occurrence, je mettrais {{?|pehlevi}} et {{hébreu}} (pour le mot en début de ligne juste en dessous) --Hélène (d) 3 mai 2012 à 14:17 (UTC)- Merci j'utiliserai ce modèle. Mais au cas où (bon j'ai pas encore cherché mais ça peut se présenter) que je ne soit pas certain des symboles, je mettre quelque chose qui soulignera ? Où je le signale simplement en résumé de la modif ? --Shimegi (d) 3 mai 2012 à 14:27 (UTC)
- Si tu ne sais pas de quelle langue il s'agit, il suffit de mettre {{?}} tout seul, et la page sera catégorisée comme comportant des caractères inconnus…. d'autres iront voir :) --Hélène (d) 3 mai 2012 à 14:35 (UTC)
- Ok merci :) --Shimegi (d) 4 mai 2012 à 06:11 (UTC)
- En l’occurrence, Unicode dispose des caractères pehlevis (blocs U+10B60–U+10B7F et U+10B40–U+10B5F) mais aucune police d’écriture n’existe pour rendre ces caractères… Donc dans cet exemple précis, il vaut sans doute mieux utiliser une image (à moins que quelqu’un crée une police ad hoc et l’implémente dans WebFont). Cdlt, VIGNERON * discut. 2 juin 2012 à 20:19 (UTC)
- Ok merci :) --Shimegi (d) 4 mai 2012 à 06:11 (UTC)
- Si tu ne sais pas de quelle langue il s'agit, il suffit de mettre {{?}} tout seul, et la page sera catégorisée comme comportant des caractères inconnus…. d'autres iront voir :) --Hélène (d) 3 mai 2012 à 14:35 (UTC)
- Merci j'utiliserai ce modèle. Mais au cas où (bon j'ai pas encore cherché mais ça peut se présenter) que je ne soit pas certain des symboles, je mettre quelque chose qui soulignera ? Où je le signale simplement en résumé de la modif ? --Shimegi (d) 3 mai 2012 à 14:27 (UTC)
Symbole pour signaler un fragment dans Pascal[modifier]
Bonsoir,
Dans l'édition "préoriginale" des Pensées, l'imprimeur a utilisé un caractère assez curieux pour signaler les fragments de texte : on dirait un * avec un crochet voir ici par ex.
Je pensais utiliser une astérisque, à défaut de trouver un caractère similaire (la reproduction à l'identique n'étant pas indispensable car le caractère signifie "seulement" qu'il s'agit d'un nouveau fragment, il n'a aucun sens "intrinsèque".
Malheureusement, l'astérisque en début de paragraphe provoque une puce... et n'est donc pas utilisable...
Quelqu'un pourrai-il m'aider à trouver un caractère de rechange ?
Merci d'avance, --Hélène (d) 8 juin 2012 à 18:13 (UTC)
PS : en attendant, j'ai utilisé un § pour éviter la mise en liste... ;)
- Tu devrais pouvoir trouver un caractère qui te plait ici : w:Astérisque#Codage_informatique. Aristoi (d) 11 juin 2012 à 09:55 (UTC)
- Chou blanc, je ne trouve rien dans Unicode (même en essayant des compositions, je ne trouve aucun diacritique correspondant à une crochet sur le côté).
- Sinon, je ne connaissais pas mais Orthotypograhie dit que les astérisques peuvent marquer le début d’un paragraphe et notamment que les astérismes (⁂) peuvent servir à introduire « les maximes ou les aphorismes » (source). Donc en attendant mieux, je te propose soit d’utiliser des astérismes, soit d’utiliser un signe similaire (cf. le lien donné par Aristoi), soit enfin d’utiliser l’astérisque classique précédé d’un
<nowiki/>. - Cdlt, VIGNERON * discut. 11 juin 2012 à 15:03 (UTC)
Utilisation de l'astérisme pour représenter un ornement typographique[modifier]
L'astérisme, si je m'en reporte aux articles des diverses versions linguistiques de Wikipédia (tel w:fr:Astérisme (typographie) pour la version francophone) semble être un signe de ponctuation rare utilisé pour « attirer l’attention sur un passage ».
Aucune source ne permet d'affirmer que c'est l'astérisme et non trois astérisques sur deux lignes, avec un espace entre les deux astérisques se retrouvant sur la même ligne, qui est utilisé.
Je me demande donc l'opportunité sur Wikisource d'utiliser le caractère unicode de l'astérisme comme séparateur de chapitres, alors même que la page montre la présence de l'espace sus-décrit, comme par exemple sur Page:Redon_-_À_soi-même,_1922.djvu/70. --Dereckson (d) 7 août 2012 à 16:29 (UTC)
- Bonjour Dereckson,
- en fait, tu as amputé la citation de Wikipedia, la phrase complète est "employé pour attirer l’attention sur un passage ou pour séparer les sous-chapitres d’un livre." - c'est très précisément l’emploi qui en est fait dans la page de Redon…
- Je ne comprends donc pas bien l'objet de ta question… :) --Hélène (d) 8 août 2012 à 08:23 (UTC)
- Ah oui, pardon pour cet oubli, c'est justement à propos de ce passage que je disais « Aucune source ne permet d'affirmer que c'est l'astérisme et non trois astérisques sur deux lignes, avec un espace entre les deux astérisques se retrouvant sur la même ligne, qui est utilisé. ». --Dereckson (d) 8 août 2012 à 09:47 (UTC)
- Cet article Wikipédia est une catastrophe, je viens de l’améliorer rapidement mais il y a encore beaucoup à faire. Techniquement, un astérisme ou trois astérisques c’est la même chose, il est probable que la plupart des composteurs ne disposaient pas d’un plomb spécifique pour l’astérisme, n’empêche que quand ils mettaient trois astérisques ensemble, ça formait un astérisme. Aujourd’hui, avec Unicode (le codage de Mediawiki), on dispose d’un caractère spécifique, pourquoi s’en priver ? Cela évite un bricolage CSS de trois astérisques qui pourrait être plus ou moins bien supportés selon les navigateurs et les systèmes. Cdlt, VIGNERON * discut. 7 septembre 2012 à 15:19 (UTC)
- Ah oui, pardon pour cet oubli, c'est justement à propos de ce passage que je disais « Aucune source ne permet d'affirmer que c'est l'astérisme et non trois astérisques sur deux lignes, avec un espace entre les deux astérisques se retrouvant sur la même ligne, qui est utilisé. ». --Dereckson (d) 8 août 2012 à 09:47 (UTC)
Dans ce livre, dans les 10 pages restant à corriger, il y à un espèce de Z tarabiscoté, si vous avez une idée de ce qu'il représente et une solution pour le faire figurer, Merci de m'en informer --Le ciel est par dessus le toit (d) 18 février 2013 à 10:05 (UTC)
- Les symboles astronomiques relativement sont courant en botanique (et en biologie) : ♃ Jupiter pour les vivaces, ♄ Saturne pour les ligneux, etc. Par contre, j’ai du mal à trouver les quatre caractères pour les arbrisseaux, arbustes, petits arbres, et grands arbres (on dirait quatre variantes du symboles de Saturne, je n’avais encore jamais vu cela). Je regarde ça de plus près.
- Cdlt, VIGNERON * discut. 2 mars 2013 à 11:26 (UTC)
- Merci Vigneron --Le ciel est par dessus le toit (d) 2 mars 2013 à 11:40 (UTC)
- Bon apparemment la seule variante Unicode est 🜪 (utilisé en alchimie pour le « minerai de plomb » vu que ♄ est aussi le plomb en alchimie). Celui-ci codé en 1F72A depuis octobre 2012, la plupart des polices ne peuvent pas encore l’afficher… Ça plus le fait que la correspondance est imparfaite, je déconseillerais son utilisation.
- Du coup, soit on utilise 4 fois le même caractère ♄, soit on utilise des fichiers images. Cdlt, VIGNERON * discut. 2 mars 2013 à 11:46 (UTC)
- Pour le Z tarabiscoté, j'ai ajouté le caractère "minerai de plomb" dans le Modèle:Caractère et l'ai utilisé dans [6]. Pouvez-vous vérifier si c'est bon en vous en servant ? Faut-il d'autres caractères, de quelles formes, de quels noms ? --Rical (d) 5 février 2014 à 01:05 (UTC)
- Merci Vigneron --Le ciel est par dessus le toit (d) 2 mars 2013 à 11:40 (UTC)
Graphie alternative du tau et caractère hébreu avec deux points[modifier]
Deux problèmes sur cette page :
- ligne 8 de la première colonne, on propose une graphie alternative pour le τ, mais je n'en vois trace nulle part.
- fin du 3e paragraphe de la 2e colonne, un ט avec deux points au-dessus ; je ne sais pas comment rendre ça.
Merci d'avance pour vos idées, --Acélan (d) 16 novembre 2013 à 09:39 (UTC)
- Bonjour Acélan (d · c · b)
- Je n’ai rien trouvé dans Unicode pour la graphie alternative du tau (et j’ai bien peur que ce soit le genre de glyphes qu’Unicode ne possédera jamais) même en cherchant dans des écritures similaires comme le phénicien (mais le tau phénicien ne correspond pas non plus graphiquement : 𐤕). Faute de mieux, il faudrait donc en faire une image…
- Pour l’hébreu, j’ai l’impression qu’il s'agit d’un gershayim ֞ט (si un spécialiste de la numération hébraïque passe par là, Acer11 (d · c · b) ?).
- Cdlt, VIGNERON * discut. 22 janvier 2014 à 19:25 (UTC)
- J'ai fais les précédents et je vais faire aussi celui-là, mais quand je pourrai.
- Pour ça, j'utilise Inskscape et je reprends un des caractères du Modèle:Caractère.
- Mais il faut faire attention de ne pas copier-coller la courbe de contour du caractère car alors le fond du caractère n'est plus transparent. Il faut seulement déplacer les points de construction de la courbe et éventuellement en ajouter ou en enlever. --Rical (d) 23 janvier 2014 à 14:55 (UTC)
- Il s'agit d'une graphie cursive que perso j'ai découvert avec le Trévoux, mais qui semble assez commune jusqu'au XVIIIe. C'est la première fois que je vois explicité le fait qu'il s'agit d'une graphie alternative et même si j'étais sur du truc, je suis bien content de cette explicitation.
- J'ai corrigé la dernière lettre hébraïque du premier paragraphe c'est un tsadé : צ, non final, malgré tout lisible.
- Sinon bravo Vigneron, il s'agit bien d'un gershayim ֞ט qu'ont peut aussi noter ט״ (moi je ne sais pas faire ton ֞ט, Vigneron). --Acer11 (d) 23 janvier 2014 à 18:59 (UTC)
- PS : Le rendu ט״ me semble plus lisible, le gershayim apparaissant collé au ט dans la solution Vigneron, ce qui ne rend pas le résultat aisément compréhensible...
- @Acer11 (d · c · b) : Unicode possède deux gershayim, un caractère séparé (05F4, une signe de ponctuation selon Unicode) et un en diacritique combiné (059E, un accent selon Unicode). Le premier est plus « lisible » mais le second me parait mieux correspondre au fac-simile et je suis bien incapable de comprendre la subtilité entre les deux. Cdlt, VIGNERON * discut. 25 janvier 2014 à 20:43 (UTC)
- @VIGNERON (d · c · b) la différence entre les deux n'ai -je crois- qu'historique, mais c'est une supposition. J'ajoute que le diacritique combiné n'est pas du tout pris en compte sur la plupart des ordi que j'ai testé sur ce point, au contraire du caractère séparé... Enfin la version sur le scan doit aussi être une ancienne graphie composée de deux points au lieu de deux traits/apostrophes. --Acer11 (d) 29 janvier 2014 à 16:10 (UTC)
- @Acer11 (d · c · b) : Unicode possède deux gershayim, un caractère séparé (05F4, une signe de ponctuation selon Unicode) et un en diacritique combiné (059E, un accent selon Unicode). Le premier est plus « lisible » mais le second me parait mieux correspondre au fac-simile et je suis bien incapable de comprendre la subtilité entre les deux. Cdlt, VIGNERON * discut. 25 janvier 2014 à 20:43 (UTC)
J'ai créé le caractère "tau grec" dans le Modèle:Caractère et l'ai utilisé page 783. Mais il laisse un grand espace devant et je ne sais pas pourquoi. Faut-il créer aussi le gershayim, et sous quel nom exact ? --Rical (d) 27 janvier 2014 à 23:44 (UTC)
- Merci à tous deux ; la page est maintenant corrigée :) --Acélan (d) 28 janvier 2014 à 07:14 (UTC)
Correction de grec ancien.[modifier]
Bonjour,
Quelqu'un aurait-il la gentillesse de corriger le court passage en grec ancien sur cette Page:Œuvres de Louise Ackermann.djvu/124 ?
Je ne suis pas parvenu à mettre les accents dans le bon sens, et je ne suis pas sûr d'avoir transcrit les bons caractères. Merci pour votre aide ! --M0tty (d) 10 décembre 2013 à 09:42 (UTC)
- Fait
 --Acélan (d) 10 décembre 2013 à 11:19 (UTC)
--Acélan (d) 10 décembre 2013 à 11:19 (UTC)
Ce cadre est une transclusion Source : Wikisource:Scriptorium/Février 2014
Diacritiques[modifier]Bonjour, Je ne sais pas quelles diacritiques utiliser ici : Page:Burnouf - La Bhagavad-Gîtâ.djvu/12, Page:Burnouf - La Bhagavad-Gîtâ.djvu/13. Une idée ? Merci d'avance. Yann (d) 10 février 2014 à 09:06 (UTC)
--Eric Y Muller (d) 10 février 2014 à 23:32 (UTC)
Vu qu’il n’y a pas de caractère Unicode pour le i souscrit, on peut toujours l’obtenir avec formatage : Voir les modèles w:en:Template:Underset ou w:en:Template:Overset pour ce genre de formatage. Pour le dha, c’est bien d͑ qu’il faut utiliser, le positionnement du diacritique n’est pas plus problématique que sur les autres lettres, ou son absence de la police utilisée par Yann n’indique en rien qu’il soit incorrect. --Moyogo (d) 26 mars 2014 à 06:05 (UTC)
|
Caractères grecs avec ~[modifier]
Bonjour, dans Page:Le Goffic - Poésies complètes, 1922.djvu/39 à vérifier: deux caractères grecs surmontés de ce qui ressemble à ~ . --Havang(nl) (d) 24 avril 2014 à 10:33 (UTC)
- C'est relu. --Acélan (d) 24 avril 2014 à 12:49 (UTC)
Variante de tau[modifier]
Bonjour,
Dans [7], il y a une note dans le bas qui comprend un texte en grec ancien dont l'une des lettres m'est inconnue. En effet, dans le troisième mot, la deuxième lettre m'est inconnue malgré toutes mes recherches (σ?τρατειας). Elle revient dans les notes et ça m'embête de ne pas savoir.
En comparant avec une autre version de l'ouvrage, j'ai découvert qu'il s'agit d'une variante de la lettre τ, mais je ne parviens à trouver son code Unicode. Cependant la version de Gallica écrit un mot un peu différent [8]. Une version dans Google [9] contient un mot plutôt différent. Je ne sais que penser.
Cantons-de-l'Est (d) 27 mai 2014 à 01:28 (UTC)
- Bonjour Cantons-de-l'Est (d · c · b),
- Après recherches et réflexions, je me dis que l’imprimeur de cet édition maîtrisait mal le grec et/ou sa composition. Je n’ai jamais vu ce glyphe nul part et je n’en trouve aucune trace (à la limite une symétrie verticale du taw phénicien 𐤕 dans sa variante « barre à crochet » mais cela me semble capillotracté).
- D’ailleurs, Cbonnery (d · c · b) a corrigé la page avec raison ; dans la version de Gallica comme de Google, c’est bien le même mot (plus d’occurrences ailleurs ici). La version de Google utilise un sigma final en initiale et ajoute des diacritiques mais c’est bien le même mot.
- Cdlt, VIGNERON * discut. 8 juin 2014 à 16:42 (UTC)
- VIGNERON : Cbonnery m'a orienté vers cette table, qui comprend les lettres grecques manuscrites. Il y a aussi cette table de Faulmann. Il s'agit bien de la lettre tau. Je suis heureux que vous confirmiez mes soupçons d'une autre façon. Cantons-de-l'Est (d) 8 juin 2014 à 20:26 (UTC)
ï̂[modifier]
Chers et savants wikisourciers,
J’aimerais savoir si vous avez déjà rencontré le caractère « ï̂ » (en français ou d’autres langues) ?
Pour ma part j’ai réuni les quelques éléments trouvés dans :
Cord. Alphabeta (d) 21 décembre 2014 à 13:15 (UTC)
- Bonjour Alphabeta (d · c),
- Je ne me souviens pas avoir jamais croisé cette combinaison de signes diacritiques (j’ai donc lu la page du Wiktionnaire avec d’autant plus d'intérêt).
- Vu la complexité du caractère, il faudrait sans doute plutôt regarder du côté des diverses transcriptions, translittérations, romanisations, etc. que du côté des langues naturelles. J’ai trouvé ce caractère dans la romanisation ISO 843 de l’alphabet grec (via l’article frwiki w:Ï̂, cet article étant le seul à contenir ce caractère sur frwiki et je ne l’ai pas trouvé sur d'autres projets de la Foundation, or du wiktionnaire francophone évidemment ;) ).
- Cdlt, VIGNERON * discut. 21 décembre 2014 à 14:15 (UTC)
- Merci VIGNERON (d · c),
- J’ai ajouté dans wikt:fr:ï̂ le renvoi vers w:fr:Ï̂ qui manquait...
- J’ai ajouté dans w:fr:Ï̂ le renvoi vers wikt:fr:ï̂ qui manquait...
- Cord. Alphabeta (d) 21 décembre 2014 à 15:04 (UTC)
- Merci Alphabeta. Je m’occuperais de l’élément Wikidata dès que possible. Cdlt, VIGNERON * discut. 22 décembre 2014 à 10:51 (UTC)
- Au passage : contrairement à ce qu’indique w:fr:Ï̂#Utilisation je n’ai pas trouvé trace du caractère « ï̂ » dans w:fr:ISO 843... Alphabeta (d) 22 décembre 2014 à 13:38 (UTC)
- Tu veux dire que tu ne l'a pas trouvé dans l’article (mais Wikipédia n'est pas toujours fiable ni exhaustif donc ce n’est pas étonnant) ou bien dans la norme elle-même ? Dans les deux cas, je te suggère de contacter l'auteur de l'information pour avoir plus de précisions. Cdlt, VIGNERON * discut. 23 décembre 2014 à 12:11 (UTC)
- Par « w:fr:ISO 843 » je désignais l’article de Wikipédia (w:fr:) : je n’y ai pas trouvé mention du caractère « ï̂ ».
- Je n’ai pas réussi à accéder à la norme ISO 843 proprement dite : j’ai l’impression que l’accès à cette norme est payant sur le Web. Alphabeta (d) 23 décembre 2014 à 17:37 (UTC)
- Tu veux dire que tu ne l'a pas trouvé dans l’article (mais Wikipédia n'est pas toujours fiable ni exhaustif donc ce n’est pas étonnant) ou bien dans la norme elle-même ? Dans les deux cas, je te suggère de contacter l'auteur de l'information pour avoir plus de précisions. Cdlt, VIGNERON * discut. 23 décembre 2014 à 12:11 (UTC)
- Au passage : contrairement à ce qu’indique w:fr:Ï̂#Utilisation je n’ai pas trouvé trace du caractère « ï̂ » dans w:fr:ISO 843... Alphabeta (d) 22 décembre 2014 à 13:38 (UTC)
- Merci Alphabeta. Je m’occuperais de l’élément Wikidata dès que possible. Cdlt, VIGNERON * discut. 22 décembre 2014 à 10:51 (UTC)
symbole sur une page du Rozier[modifier]
Bonsoir,
J'ai un souci sur cette page où figure un symbole que je n'ai pas trouvé. Pouvez-vous, s'il vous plaît, m'indiquer s'il existe ou s'il faut insérer l'image ? D'avance merci. Gtaf (d) 5 janvier 2015 à 18:54 (UTC)
- Pour moi, c'est simplement un 'phi' majuscule: Φ. Dispo dans caractères speciaux -> grec. --LBE (d) 6 janvier 2015 à 09:03 (UTC)
- On peut effectivement penser à un Phi majuscule, mais la graphie affichée n'est pas satisfaisante. On a mieux en utilisant . --Acélan (d) 6 janvier 2015 à 10:54 (UTC)
- Merci à tous les deux. Bravo Acélan pour cette solution, que j'ai ajoutée sur la page. Gtaf (d) 6 janvier 2015 à 19:22 (UTC)
- On peut effectivement penser à un Phi majuscule, mais la graphie affichée n'est pas satisfaisante. On a mieux en utilisant . --Acélan (d) 6 janvier 2015 à 10:54 (UTC)

Je ne parviens pas à saisir un caractère à la 17262è ligne de la chanson des quatre fils Aymont. Quelqu'un est-il à l'aise avec ce genre de problème moyenâgeux ?
- Bonjour 109.89.45.13 (d · c · b)
- On parle bien du vers « Si est saillis en Sainne, bien lo puet l'an veïr. » ? Je n'y vois pas de problème particulier, serait-il possible de savoir où et quel est le problème ?
- Cdlt, VIGNERON * discut. 3 août 2015 à 08:25 (UTC)
- Zut, il s'agissait du 17261 : « Si a fait .I. eslais, nel pot contretenir, » --Hildepont (d) 4 août 2015 à 21:36 (UTC)
- Je comprends mieux. J’avais justement mis en forme ce « un ». Cdlt, VIGNERON * discut. 5 août 2015 à 07:47 (UTC)
- Ce n'est rien d'autre que la notation entre points de chiffres romains (on trouve aussi ce marquage en grec et d'autres écritures pour indiquer leur lecture en tant que nombre et non en tant qu'orthographe d'un mot ; on la trouve aussi dans les notations en Braille). C'est une pratique ancienne datant d'avant l'adoption de chiffres ou nombres distinctifs. Ce n'est pas moyenâgeux, car c'est encore très commun aujourd'hui dans de nombreuses langues modernes pour des raisons purement stylistiques, parfois pour distinguer aussi plusieurs systèmes concurrents de numération sans alourdir trop le texte d'annotations en clair.
- Les sciences font un usage encore abondant de divers diacritiques et symboles pour "décorer" des chiffres ou nombres et leur donner une sémantique distinctive supplémentaire sans pour autant ajouter des couleurs ou trop changer la taille des glyphes et l'interlignage dans le reste du texte ou pour compacter des tableaux riches en données. — Verdy_p (d) 6 octobre 2019 à 22:52 (UTC)
- Ce n'est rien d'autre que la notation entre points de chiffres romains (on trouve aussi ce marquage en grec et d'autres écritures pour indiquer leur lecture en tant que nombre et non en tant qu'orthographe d'un mot ; on la trouve aussi dans les notations en Braille). C'est une pratique ancienne datant d'avant l'adoption de chiffres ou nombres distinctifs. Ce n'est pas moyenâgeux, car c'est encore très commun aujourd'hui dans de nombreuses langues modernes pour des raisons purement stylistiques, parfois pour distinguer aussi plusieurs systèmes concurrents de numération sans alourdir trop le texte d'annotations en clair.
- Je comprends mieux. J’avais justement mis en forme ce « un ». Cdlt, VIGNERON * discut. 5 août 2015 à 07:47 (UTC)
- Zut, il s'agissait du 17261 : « Si a fait .I. eslais, nel pot contretenir, » --Hildepont (d) 4 août 2015 à 21:36 (UTC)
Questions sur les symboles mathématiques[modifier]
Voir ici, le 5 août 2015 et ici, même date, le jeu des « Sept Erreurs ». Des Wikisourciens compétents peuvent-ils aider Paul-Eric Langevin ? --Zyephyrus (d) 5 août 2015 à 18:21 (UTC)
 Paul-Eric Langevin : J’ai regardé, les erreurs sont dues à des tirets autres que le signe moins. LaTeX ne les aime pas, il suffit de les remplacer par un - est ça fonctionne.
Paul-Eric Langevin : J’ai regardé, les erreurs sont dues à des tirets autres que le signe moins. LaTeX ne les aime pas, il suffit de les remplacer par un - est ça fonctionne.- En dehors de ces erreurs, j’ai un doute quant à l’import de ces textes, pour deux raisons : 1° ils n’ont pas de fac-similé, c’est dommage ; 2° Langevin n’est mort qu’en 1946, il ne sera donc dans le domaine public qu’en 2017. Il vaudrait donc mieux attendre un an et demi. Aristoi (d) 5 août 2015 à 20:28 (UTC)
- Je vais essayer de regarder cela avec le conseil ci-dessus concernant les tirets; d'autre part, je ne sais pas ce que vous entendez par fac-similé, éclairez-moi; enfin, la question du domaine public est effectivement une question que je me suis posée en faisant le même calcul, cependant il existait déjà trois ou quatre textes de mon grand-père, dont deux en français, sur wikisource avant que je ne commence mon apport personnel.Cordialement --Paul-Eric Langevin 6 août 2015 à 00:00 (UTC)
- Merci Zyephyrus et Aristoi, j'ai corrigé les 7 erreurs de syntaxe dans le premier texte, ainsi que les 4 erreurs de syntaxe dans le second texte, les deux sont maintenant complets et prêts à être vérifiés par Wikisource.Cordialement --Paul-Eric Langevin 6 août 2015 à 00:34 (UTC)
- Je vais essayer de regarder cela avec le conseil ci-dessus concernant les tirets; d'autre part, je ne sais pas ce que vous entendez par fac-similé, éclairez-moi; enfin, la question du domaine public est effectivement une question que je me suis posée en faisant le même calcul, cependant il existait déjà trois ou quatre textes de mon grand-père, dont deux en français, sur wikisource avant que je ne commence mon apport personnel.Cordialement --Paul-Eric Langevin 6 août 2015 à 00:00 (UTC)
Écriture gothique[modifier]
Bonjour,
Est-ce que vous savez comment composer un mot en caractères gothiques ? Voir Page:Alfred de Bougy - Le Tour du Léman.djvu/400:
—C.P. 17 août 2015 à 16:19 (UTC)
- Bonjour C.P.. Il y a le modèle {{Gothique|Alleinig}}, mais le rendu (Alleinig) n'est pas tout à fait le même que sur le FS... Cordialement, --*j*jac (d) 17 août 2015 à 17:00 (UTC)
- Merci,... mais ce modèle ne fonctionne pas pour les lecteurs qui n’ont pas la police UnifrakturMaguntia installée sur leur système. Il manque quelque part un lien pour récupérer la police (du genre:
<link rel="stylesheet" href="https://fonts.googleapis.com/css?family=UnifrakturMaguntia" />) —C.P. 17 août 2015 à 17:45 (UTC) - Je vais voir si je peux réparer à partir du modèle en:s:Template:Blackletter, qui, lui, fonctionne. —17 août 2015 à 17:53 (UTC)
- Il faut aller dans: Spécial:Préférences → 1er onglet «Informations personnelles» → section «Internationalisation» → «Plus de paramètres de langues» → «Télécharger les polices si nécessaire». Ce paramètre semble activé par défaut (y compris si l’on n’est pas connecté) sur en.wikisource, et désactivé par défaut sur fr.wikisource. —C.P. 17 août 2015 à 18:15 (UTC)
- Un admin pourrait peut-être le passer en par défaut ?--- Luc - (d) 15 novembre 2015 à 00:35 (UTC)
- Il faut aller dans: Spécial:Préférences → 1er onglet «Informations personnelles» → section «Internationalisation» → «Plus de paramètres de langues» → «Télécharger les polices si nécessaire». Ce paramètre semble activé par défaut (y compris si l’on n’est pas connecté) sur en.wikisource, et désactivé par défaut sur fr.wikisource. —C.P. 17 août 2015 à 18:15 (UTC)
- Merci,... mais ce modèle ne fonctionne pas pour les lecteurs qui n’ont pas la police UnifrakturMaguntia installée sur leur système. Il manque quelque part un lien pour récupérer la police (du genre:
℟ et ℣[modifier]
Bonjour,
Je ne sais comment documenter dans Wikisource le signe
- ℟ (lien rouge au moins pour l’heure)
ainsi que le signe
- ℣ (lien rouge au moins pour l’heure)
ni même s’il convient de le faire. En tout cas suite à :
et
les entrées et articles suivants ont été créés :
Cord. Alphabeta (d) 29 octobre 2015 à 15:06 (UTC)
- Je viens de « découvrir » Wikisource:Glyphes & caractères/Question#Verset (question remontant à 2010) où il semble bien être question du caractère ℣ appelé « verset » (et aussi « versicule » : voir le Wiktionnaire et Wikipédia). Je précise que le caractère ℟ est appelé « répons ». J’ignore ce qu’est la « page "collecte" »... Alphabeta (d) 29 octobre 2015 à 15:13 (UTC)
- À moins qu'un texte soit intitulé ℟, ce lien restera rouge (probablement pour longtemps mais il faut jamais sous-estimer de la créativité des auteurs, on a bien deux textes intitulés ?).
- Cet espace est constitué de deux pages : celle pour les questions (ici-même) et celle où l'on collecte et synthétise les réponses : Wikisource:Glyphes & caractères/Collecte. Le but est d'aider les wikisourciers à retranscrire les textes quand ils tombent sur des caractères qu'ils ne connaissent pas.
- L'entrée wikt:fr:℣ et l'article w:fr:℣ ne parlent pas des acceptions correspondant aux acceptions recensées dans l’Encyclopédie.
- Cdlt, VIGNERON * discut. 29 octobre 2015 à 16:59 (UTC)
- L’ouvrage est grande...
- Alors merci de compléter wikt:fr:℣ et w:fr:℣ si vous maîtriser le sujet.
- Pour ma part j’ai un problème récurrent avec Wikisource : je n’ai pas réussi à faire afficher la liste des pages de Wikisource comportant le caractère « ℣ ».
- Quant à demande de source rajoutée dans w:fr:℣. Il y quand même le document Unicode en français. Et on a aussi tenu compte de wikt:en:℟ (en anglais).
- Ceci dit un verset (terme auquel est attaché le symble ℣) n’appelle un répons que dans la liturgie je suppose.
- Alphabeta (d) 29 octobre 2015 à 18:55 (UTC)
-
- Ce que j’avais mis dans w:fr:℣ correspond bien à ce que j’avais lu dans http://gallica.bnf.fr/ark:/12148/bpt6k2053661.r=.langFR . Voir les paragraphes Liturgie et Typographie de l’entrée « verset » de la page 938. J’ai rajouté ce « ref » dans w:fr:℣. Remonter à l’Encyclopédie a un intérêt historique : on vous laisse faire sur ce point. Alphabeta (d) 30 octobre 2015 à 10:11 (UTC). PS : Meilleur lien (car direct sur la page) : http://gallica.bnf.fr/ark:/12148/bpt6k2053661/f942.image . Alphabeta (d) 30 octobre 2015 à 11:03 (UTC)
-
- À VIGNERON (d · c · b) (« Vigneron ») : à propos « des acceptions correspondant aux acceptions recensées dans l’Encyclopédie » : j’aimerais disposer de plusieurs exemples. Pour le signe « ℣ » la page s:fr:Wikisource:Glyphes & caractères/Collecte (Wikisource:Glyphes & caractères/Collecte) renvoie à s:fr:Page:Diderot - Encyclopedie 1ere edition tome 10.djvu/47 (Page:Diderot - Encyclopedie 1ere edition tome 10.djvu/47) (au passage : il y a chevauchement entre la transcription et le facsimilé sur mon écran) où j’ai effectivement trouvé une occurrence du figne « ℣ » : « selon l’Ecriture qui nous apprennent qu’il n’y avoit rien dans l’arche que les tables de l’alliance (Exod. xxv, 16. I. Rois viij. 9. II. chron. ℣. 10.) » mais je vois une difficulté d’interprétation. Les deux premières citations se composent en 1) nom du livre de la bible 2) numéro de chapitre en chiffres romains 3) numéro de verset en chiffres arabes. Dans le troisième citation, le signe « ℣ » se substitue à un numéro de chapitre en chiffres romains : se pourrait donc être une coquille ou bien un caractère inédit notant un chiffre romain (j’ai pensé à « IV » par exemple). Et pour l’heure je n’ai pas trouvé le temps de lire en entier le second livre des Chronique (livre documenté dans w:fr:Deuxième livre des Chroniques) pour retrouver où il y serait question de l’arche... Cordialement. Alphabeta (d) 31 octobre 2015 à 11:02 (UTC). PS : À VIGNERON (d · c · b) (« Vigneron ») : Eurêka : il s’agit du verset 10 du chapitre 5. Voir s:fr:Bible Segond 1910/Deuxième livre des Chroniques (Bible Segond 1910/Deuxième livre des Chroniques : « 10. Il n’y avait dans l’arche que les deux tables que Moïse y plaça en Horeb, lorsque l’Éternel fit alliance avec les enfants d’Israël, à leur sortie d’Égypte. » Il ne reste plus qu’à signaler dans s:fr:Page:Diderot - Encyclopedie 1ere edition tome 10.djvu/47 (Page:Diderot - Encyclopedie 1ere edition tome 10.djvu/47) — mais je sais pas faire — que le caractère « ℣ » qu’on y trouve n’est qu’est une coquille pour « v » ! Alphabeta (d) 31 octobre 2015 à 12:27 (UTC)
- Fait [10]. --Pikinez (d) 1 novembre 2015 à 18:17 (UTC)
Pikinez (d · c · b) défait. Cela ne me semble pas être une coquille (ou alors, à chaque fois que les Encyclopédistes ont voulu abréger verset, ils auraient fait la même coquille en prenant le même symbole recommandé par les typographes ; cela me semble improbable sinon impossible).Ooups, ici c'est bien une coquille car le mot verset est omis.- Alphabeta (d · c · b) sur la page Page:Diderot - Encyclopedie 1ere edition tome 10.djvu/47 il y a deux occurrences de ℣ ; il y a des dizaines sinon des milliers d'autres occurrences dans l'Encyclopédie (le moteur de recherche ne comprend pas certains caractères Unicode avancés mais il suffit de prendre une entrée de l'Encyclopédie sur un sujet religieux pour en trouver). Il y a aussi une occurrence à la page Page:Diderot - Encyclopedie 1ere edition tome 1.djvu/97 (où le contexte est monétaire et non liturgique).
- Cdlt, VIGNERON * discut. 2 novembre 2015 à 09:18 (UTC)
- Dans Page:Diderot - Encyclopedie 1ere edition tome 10.djvu/47 il existe effectivement une deuxième occurrence du signe « ℣ » : « & c’est à cette idée qu’ils appliquent ce que le Psalmiste dit au pseaume 23. ℣ 6. Tu dresses ma table devant moi, à la vûe de ceux qui me pressent » Je ne m’en étais pas avisé du fait du chevauchement entre le facsimilé et la transcription dont j’ai déjà fait état supra. Qui peut prendre le temps de vérifier si le psaume 23 est divisé en chapitres ou pas ? Merci d’avance. Alphabeta (d) 2 novembre 2015 à 12:20 (UTC). PS. J’ai vérifié s:fr:Bible Segond 1910/Livre des Psaumes#Psaume 23 (Bible Segond 1910/Livre des Psaumes#Psaume 23) : pas de division en chapitre (c’est le numéro du psaume qui fait figure de numéro de chapitre au sein du Livre des Psaumes). Mais le numéro de verset indiqué par l’Encyclopédie pose problème, Segond traduisant « 6. Oui, le bonheur et la grâce m’accompagneront / tous les jours de ma vie, / et j’habiterai dans la maison de l’Éternel / jusqu’à la fin de mes jours. » Il s’agit en fait du verset 5 de la traduction de Segond : « 5. Tu dresses devant moi une table, / en face de mes adversaires ; / tu oins d’huile ma tête, / et ma coupe déborde. » (Le souligné est de moi.) Avant de décréter qu’il s’agit d’une deuxième coquille de l’Encyclopédie (« 6 » pour « 5 »), il convient d’effectuer quelques vérifications supplémentaires (le découpage en versets du psaume 23 pourrait différer entre la Bible hébraïque, grecque et latine). Pour la Bible en hébreu, selon s:fr:Psaume 23 (traduction juxtalinéaire hébreu - français) (Psaume 23 (traduction juxtalinéaire hébreu - français)) en tout cas, il s’agit bien du verset 5. Par ailleurs : Fait Fait : j’ai complété (sur le verset hors notion de répons) l’entrée wikt:fr:℣ ainsi que l’article w:fr:℣, au vu de cette citation suppémentaire de l’Encyclopédie. Alphabeta (d) 2 novembre 2015 à 14:47 (UTC)
- Dans Page:Diderot - Encyclopedie 1ere edition tome 10.djvu/47 il existe effectivement une deuxième occurrence du signe « ℣ » : « & c’est à cette idée qu’ils appliquent ce que le Psalmiste dit au pseaume 23. ℣ 6. Tu dresses ma table devant moi, à la vûe de ceux qui me pressent » Je ne m’en étais pas avisé du fait du chevauchement entre le facsimilé et la transcription dont j’ai déjà fait état supra. Qui peut prendre le temps de vérifier si le psaume 23 est divisé en chapitres ou pas ? Merci d’avance. Alphabeta (d) 2 novembre 2015 à 12:20 (UTC). PS. J’ai vérifié s:fr:Bible Segond 1910/Livre des Psaumes#Psaume 23 (Bible Segond 1910/Livre des Psaumes#Psaume 23) : pas de division en chapitre (c’est le numéro du psaume qui fait figure de numéro de chapitre au sein du Livre des Psaumes). Mais le numéro de verset indiqué par l’Encyclopédie pose problème, Segond traduisant « 6. Oui, le bonheur et la grâce m’accompagneront / tous les jours de ma vie, / et j’habiterai dans la maison de l’Éternel / jusqu’à la fin de mes jours. » Il s’agit en fait du verset 5 de la traduction de Segond : « 5. Tu dresses devant moi une table, / en face de mes adversaires ; / tu oins d’huile ma tête, / et ma coupe déborde. » (Le souligné est de moi.) Avant de décréter qu’il s’agit d’une deuxième coquille de l’Encyclopédie (« 6 » pour « 5 »), il convient d’effectuer quelques vérifications supplémentaires (le découpage en versets du psaume 23 pourrait différer entre la Bible hébraïque, grecque et latine). Pour la Bible en hébreu, selon s:fr:Psaume 23 (traduction juxtalinéaire hébreu - français) (Psaume 23 (traduction juxtalinéaire hébreu - français)) en tout cas, il s’agit bien du verset 5. Par ailleurs : Fait
-
- « ℣ » n’est pas un symbole monétaire ! À propos de « [i]l y a aussi une occurrence à la page Page:Diderot - Encyclopedie 1ere edition tome 1.djvu/97 (où le contexte est monétaire et non liturgique) » : j’ai consulté soigneusement s:fr:Page:Diderot - Encyclopedie 1ere edition tome 1.djvu/97 (Page:Diderot - Encyclopedie 1ere edition tome 1.djvu/97) : le caractère « ℣ » trouvé dans la transcription n’est pas exactement celui qu’on trouve dans le facsmilé pour symboliser le « sou commun » en « holland(o/a)is » ; on conseille donc d’utiliser dans la transcription (au lieu et place du caractère « ℣ ») une image extraite du facsimilé de la page (comme il a été fait pour d’autres symboles monétaires apparaissant dans cette page de l’Encyclopédie). Je suppose que ce symbole du « sou commun » en « holland(o/a)is » n’apparaît que rarement dans l’Encyclopédie. Et je n’ai rien trouvé dans les documents Unicode qui suggère que le caractère « ℣ » puisse être utilisé comme symbole monétaire. Salut amical à VIGNERON (d · c · b) (« Vigneron »). Alphabeta (d) 2 novembre 2015 à 17:34 (UTC)
- Cela part un peu dans tout les sens, je sépare en plusieurs morceaux pour plus de clarté.
- pour le problème de chevauchement, il faudrait voir avec un spécialiste de la technique (ping Tpt (d · c · b) ?)
- toute la Bible est divisée en chapitre mais pour les psaumes, c'est diablement le bazar. En gros, il faut effectivement comprendre « Psaume 23 » comme « chapitre 23 du Livre des Psaumes » (même si on n'utilise que très rarement cette formulation). Ensuite, le nombre et la division des chapitres (et a fortiori des versets au sein des chapitre) a évolué de très nombreuses fois. Je ne pense pas que 6 soit une coquille mais plus probablement la numérotation de l’époque (et il ne faut surtout pas comparer avec une édition moderne mais plutôt une version d'époque). Si on compare avec cette édition de 1789 (le plus proche temporellement que j'ai pu trouvé facilement), on voit que le découpage - et même le texte dans une certaine mesure - est différent (psaume 22 et non 23 - ce qui est toujours sa place actuelle selon la numérotation grecque - et contenant 9 versets et non 6) et surtout on voit que le texte correspondant à celui de L’Encyclopédie se trouve bien au verset 6 ; donc pas de coquille ce me semble.
- pour le sou commun hollandais (serait-ce le stuyver ?) le caractère est peut-être différent mais le glyphe me semble identique (quelle différence vois-tu ?) et il me semble donc justifié d'utiliser le caractère Unicode ℣. Surtout que connaissant la typographie de l’époque, cela m'étonnerait fort que deux plombs différents aient été fondus (c'est déjà vraiment exceptionnel qu'il y en ait eu un) et qu'en plus l'exemplaire numérique dont on parle provient de la numérisation de microfiche (ce qui diminue la qualité de la numérisation ; malheureusement, je ne trouve pas d'autre numérisation de la première édition). J'ai cherché très rapidement mais je n'en trouve aucune autre occurrence dans L’Encyclopédie (en tout cas, rien dans des articles où on s'attendrait à le trouver comme L’Encyclopédie/1re édition/SOU, L’Encyclopédie/1re édition/SOL, L’Encyclopédie/1re édition/STUYVER, etc.)
- pour les occurrences de ℣ dans L’Encyclopédie, il y a aussi (liste non-exhaustive, je n’ai fait que les 10 premiers tomes et assez rapidement) :
- Page:Diderot - Encyclopedie 1ere edition tome 1.djvu/87
- Page:Diderot - Encyclopedie 1ere edition tome 1.djvu/356
- Page:Diderot - Encyclopedie 1ere edition tome 3.djvu/366
- Page:Diderot - Encyclopedie 1ere edition tome 3.djvu/501
- Page:Diderot - Encyclopedie 1ere edition tome 10.djvu/46
- Page:Diderot - Encyclopedie 1ere edition tome 10.djvu/47
- Page:Diderot - Encyclopedie 1ere edition tome 10.djvu/57 (pour une fois ce n'est pas liturgique)
- Page:Diderot - Encyclopedie 1ere edition tome 10.djvu/62
- Page:Diderot - Encyclopedie 1ere edition tome 10.djvu/128 (idem)
- Page:Diderot - Encyclopedie 1ere edition tome 10.djvu/470
- Page:Diderot - Encyclopedie 1ere edition tome 10.djvu/718
- Page:Diderot - Encyclopedie 1ere edition tome 10.djvu/861 (idem)
- Page:Diderot - Encyclopedie 1ere edition tome 11.djvu/27
- Cdlt, VIGNERON * discut. 3 novembre 2015 à 13:22 (UTC)
- Je ne vois plus en fait qu’un seul élément faisant encore débat, celui-ci : « pour le sou commun hollandais (serait-ce le stuyver ?) le caractère est peut-être différent mais le glyphe me semble identique (quelle différence vois-tu ?) et il me semble donc justifié d'utiliser le caractère Unicode ℣. Surtout que connaissant la typographie de l’époque, cela m'étonnerait fort que deux plombs différents aient été fondus (c'est déjà vraiment exceptionnel qu'il y en ait eu un) ».
- D’abord un caractère spécial pour le sou hollandais a bel et bien été fondu pour l’Encyclopédia, que l’on trouve dans le facsimilé reproduit dans s:fr:Page:Diderot - Encyclopedie 1ere edition tome 1.djvu/97 (Page:Diderot - Encyclopedie 1ere edition tome 1.djvu/97) : Wikisource en possède du reste une image (s:fr:Fichier:Encyc ABREGÉ-Sou2.png), image que l’on trouve insérée dans s:fr:Wikisource:Glyphes & caractères/Collecte#Symboles monétaires.
- Comme on voit ce caractère
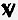 (s:fr:Fichier:Encyc ABREGÉ-Sou2.png) est plus gras que le caractère ℣. De plus la barre s’ajoutant au V comporte en élément en équerre en haut vers la gauche dans le seul caractère ℣.
(s:fr:Fichier:Encyc ABREGÉ-Sou2.png) est plus gras que le caractère ℣. De plus la barre s’ajoutant au V comporte en élément en équerre en haut vers la gauche dans le seul caractère ℣. - La prudence dicte donc de substituer (s:fr:Fichier:Encyc ABREGÉ-Sou2.png) à ℣ dans la transcription figurant dans s:fr:Page:Diderot - Encyclopedie 1ere edition tome 1.djvu/97.
- Salut amical à VIGNERON (d · c · b) (« Vigneron »). Alphabeta (d) 8 novembre 2015 à 13:06 (UTC)
- Cela part un peu dans tout les sens, je sépare en plusieurs morceaux pour plus de clarté.
- « ℣ » n’est pas un symbole monétaire ! À propos de « [i]l y a aussi une occurrence à la page Page:Diderot - Encyclopedie 1ere edition tome 1.djvu/97 (où le contexte est monétaire et non liturgique) » : j’ai consulté soigneusement s:fr:Page:Diderot - Encyclopedie 1ere edition tome 1.djvu/97 (Page:Diderot - Encyclopedie 1ere edition tome 1.djvu/97) : le caractère « ℣ » trouvé dans la transcription n’est pas exactement celui qu’on trouve dans le facsmilé pour symboliser le « sou commun » en « holland(o/a)is » ; on conseille donc d’utiliser dans la transcription (au lieu et place du caractère « ℣ ») une image extraite du facsimilé de la page (comme il a été fait pour d’autres symboles monétaires apparaissant dans cette page de l’Encyclopédie). Je suppose que ce symbole du « sou commun » en « holland(o/a)is » n’apparaît que rarement dans l’Encyclopédie. Et je n’ai rien trouvé dans les documents Unicode qui suggère que le caractère « ℣ » puisse être utilisé comme symbole monétaire. Salut amical à VIGNERON (d · c · b) (« Vigneron »). Alphabeta (d) 2 novembre 2015 à 17:34 (UTC)
Les s longs : ſ[modifier]
Bonjour,
Je suis nouveaux sur Wikisource, et je prends beaucoup de plaisir à corriger et à vérifier les pages de nombreux livres. Cependant, je ne sais pas bien si, lors de la conversion des livres scannés en texte, je dois scrupuleusement retranscrire tout les glyphes, dont le s long noté ſ pour les documents en vieux français, ou si je peux remplacer les "ſ" par des "s". J'ai cherché sur les différentes pages de documentation de Wikisource, mais je ne trouve pas de réponse à ma question. Lunavorax (d) 7 janvier 2016 à 23:27 (UTC)
- Lunavorax :Il faut retranscrire exactement les lettres telles qu'elles apparaissent. Vous pourrez rajouter le module {modernisation} dans la section transclusion pour que le lecteur puisse choisir une version modernisée du texte, donc avec des "s" normaux à la place des "ſ" et une orthographe actualisée. Bonne continuation ! --Girart de Roussillon (d) 8 janvier 2016 à 02:08 (UTC)
- Lunavorax : et Girart de Roussillon : : il ne faut pas utiliser les "ſ", c'est un choix que l'on peut faire, nuance. Personnellement, je ne les utilise jamais. Il faut savoir que, pour le moment, le texte modernisé n'apparaît que sur les pages en html, pas lors de l'export epub. --Acélan (d) 8 janvier 2016 à 07:34 (UTC)
- Bonjour et bienvenue Lunavorax (d · c) ! [[Utilisateur:{{{1}}}|{{{1}}}]] :
- Oui, vous pouvez remplacer les s longs « ſ » par des s ronds « s ». Personnellement, je le déconseille - d'autant plus pour les textes les plus anciens - mais chacun est libre de choisir le degré de fidélité et l'effort à fournir lors de la retranscription. Attention cependant, si un premier contributeur a pris la peine de retranscrire avec des s longs, il fond évidemment les laisser dans ce cas
 .
. - Pour faciliter la retranscription, il existe un gadget qui lors de la saisie remplace automatique la séquence de caractères ^s par ſ (ça simplifie drôlement la vie) ; il se nomme « Caractères spéciaux automatiques (accents, apostrophes) » et est à activer sur Spécial:Préférences#mw-prefsection-gadgets. Et pour le lecteur, il y a effectivement
{{modernisation}}(et je plussoie Acélan : vivement le jour est ce sera dans l’export). - Cdlt, VIGNERON * discut. 8 janvier 2016 à 09:22 (UTC)
- Il est tout à fait envisageable que la transformation des "ſ" en "s" dans l’export epub fonctionne un jour. Par contre il est l'est nettement moins que quelqu'un repasse sur la totalité des anciens textes pour rétablir la totalité des "ſ" transformés en "s". De plus, si quelqu'un est assez motivé pour lire un texte ancien, il l'est probablement assez pour supporter d'avoir à lire des "ſ". Je plaide donc en faveur du maintien des "ſ" dans les transcriptions. BernardM (d) 9 janvier 2016 à 14:44 (UTC)
- Il n'y a pas que des textes anciens qui sont concernés. Pour les textes médiévaux, effectivement, il faut être motivé et connaisseur, donc la question est moins sensible que dans les textes du XVIIIe, dont la langue est beaucoup plus accessible, mais où les ſ constituent un obstacle pour certains. Donc il faut continuer de laisser la liberté au correcteur d'un texte de les utiliser ou pas, surtout dans ce cas (avec, bien sûr, le respect du choix fait par le premier transcripteur, mais ça ne pose d'ordinaire pas de problème). --Acélan (d) 9 janvier 2016 à 15:17 (UTC)
- Je déconseille fortement d'utiliser le "ſ", à moins d'offrir une version alternative. Encore aujourd'hui, j'ai été extrêmement frustré de ne pas pouvoir faire de recherche plein texte dans Iconologie (Cesare Ripa, 1643), où seule existe la version avec "ſ". Si quelqu'un tient absolument à lire la version ancienne, pourquoi ne pas se référer au PDF de l'original? --Codex (d) 27 août 2020 à 17:53 (UTC)
- Bonjour à tous. Que ça fait plaisir de retrouver l'ambiance studieuse de WS !
- Lunavorax, Codex, Girart de Roussillon, Acélan, Psychoslave, Pikinez et VIGNERON : Je vous rappelle que le script d'aide (initialement pour pour le Trévoux), que j'améliore de temps en temps, fonctionne spécifiquement sur la typo du XVIIIe s., bouton dans la barre d’outil :
 . Il remplace les "ſ" par des "s", et il corrige aussi de très nombreuses scanilles fréquentes au moins avec les doc de cette époque.
. Il remplace les "ſ" par des "s", et il corrige aussi de très nombreuses scanilles fréquentes au moins avec les doc de cette époque. - De fait dans le Trévoux le ſ n’apparaît qu'en cours de mot (ou en première lettre), le s étant systématique à la fin du mot. Si qq'un a un contre-exemple, je suis très intéressé (même si je pense que c'est probablement une erreur, que je n'ai encore jamais trouvée). Une fois cette règle admise, ce serait facile de rétablir une version avec les ſ pour qq'un qui le désirerait.
- Je tiens à vous dire que je suis preneur de tous faux positifs ou déviances du script. --Acer11 (d) 27 août 2020 à 19:10 (UTC)
- Je déconseille fortement d'utiliser le "ſ", à moins d'offrir une version alternative. Encore aujourd'hui, j'ai été extrêmement frustré de ne pas pouvoir faire de recherche plein texte dans Iconologie (Cesare Ripa, 1643), où seule existe la version avec "ſ". Si quelqu'un tient absolument à lire la version ancienne, pourquoi ne pas se référer au PDF de l'original? --Codex (d) 27 août 2020 à 17:53 (UTC)
- Il n'y a pas que des textes anciens qui sont concernés. Pour les textes médiévaux, effectivement, il faut être motivé et connaisseur, donc la question est moins sensible que dans les textes du XVIIIe, dont la langue est beaucoup plus accessible, mais où les ſ constituent un obstacle pour certains. Donc il faut continuer de laisser la liberté au correcteur d'un texte de les utiliser ou pas, surtout dans ce cas (avec, bien sûr, le respect du choix fait par le premier transcripteur, mais ça ne pose d'ordinaire pas de problème). --Acélan (d) 9 janvier 2016 à 15:17 (UTC)
- Bonjour et bienvenue Lunavorax (d · c) !
Proposition d'un script pour automatiser la conversion de s ronds en s longs.[modifier]
Bonjour,
La correction manuelle de s ronds en s longs prends un certain temps, même avec la commande ^s. J'ai donc pensé à un script permettant (c'est à vérifier) de faire ce travail automatiquement. J'ai remarqué que les s ne sont longs que lorsqu'ils sont suivis d'une lettre minuscule. Ainsi le s reste rond en fin de mot ou devant une apostrophe. Par conséquent, j'ai supposé que la modifications des s ronds en s longs pouvait se faire automatiquement avec la commande suivante :sed 's/s\([a-z]\)/ſ\1/'
Cette commande recherche tous les s ronds suivis d'une lettre minuscule et les remplace par des s longs. Le seul problème est que cette commande fonctionne hors-ligne, sed étant un programme UNIX.
Avis donc, aux utilisateurs expérimentés qui auraient des suggestions pour automatiser la récupération et la correction des textes. J'ai vu que Wikisource pouvait accueillir des greffons en Lua, peut-être qu'il y a quelque chose à voir de ce côté là.--Lunavorax (d) 21 janvier 2016 à 21:25 (UTC)
- Bonjour Lunavorax,
- Cela part d'une bonne idée mais malheureusement tu fais partiellement erreur. « aussi » peut se graphier « auſi » , « ausſi » ou « außi ». Un gadget pourrait certes aider mais ce n'est pas automatique, l'utilisation de la variante contextuelle du s ayant fortement varié en fonction des époques, des auteurs, etc. Cdlt, VIGNERON * discut. 21 janvier 2016 à 22:52 (UTC)
- VIGNERON :C'est noté ! Pour ma part, j'ai ameilloré mon script et je m'en sers pour modifier automatiquement le texte avant de tout relire pour être sûr qu'aucune erreur ne s'est glissée. Cela me mâche bien 90% du travail et rend l’édition plus agréable. Le script est le suivant
xclip -out | sed 's/s\B/ſ/g' | sed 's/ et / \& /g' | xclip
Ce code prends le texte dans le presse papier et le modifie directement en remplaçant les s ronds par des s longs et les et par des &. J'ai assigné ce script à la touche F8 de mon clavier. Je coupe le texte, je presse F8, je colle, et le texte est corrigé ! À ceux que ça peux aider donc.--Lunavorax (d) 21 janvier 2016 à 23:39 (UTC)- Lunavorax : tu peux activer le gadget Typo et ajouter des lignes dans ton script personnel Utilisateur:Lunavorax/common.js ; il suffira alors d'appuyer sur le bouton « T » dans la barre d'outils pour faire le remplacement automatique. (j'utilise un script perso grâce à Tpt si mes souvenirs sont bons ! Utilisateur:Pikinez/common.js) --Pikinez (d) 22 janvier 2016 à 12:25 (UTC)
- Merci infiniment pour cette information Pikinez ! Je vais bien m'amuser avec ça je pense :) --Lunavorax (d) 22 janvier 2016 à 15:01 (UTC)
- La règle est un poil plus complexe, elle dépend du corps (romain, italique, gothique) et elle n'a probablement pas été constante dans le temps. Voir : http://babelstone.co.uk/Blog/2006/06/rules-for-long-s.html Captain frakas (d) 30 mai 2016 à 01:11 (UTC)
- Super ce gadget. J’ai commencé ma propre liste de substitutions. Lunavorax :, tu seras peut-être intéressé par les modifications que j’ai apporté pour détecter et remplacer les « et ». :) --Psychoslave (d) 13 septembre 2016 à 11:55 (UTC)
ϑ[modifier]
Bonjour. Je n'ai pas trouvé le caractère « ϑ », variante de « θ », dans la liste des caractères spéciaux. J'en ai eu besoin sur cette page. Vous avez peut-être de meilleurs yeux que les miens :-\ R [CQ, ici W9GFO] 13 avril 2016 à 16:19 (UTC)
- Reptilien.19831209BE1 : Effectivement, il est absent mais j'hésite à l’ajouter... Si on ajoute cette variante, pourquoi pas toutes les autres ? et dans ce cas, il en manque plusieurs centaines... Cela ne va-t-il pas avoir l'effet inverse et rendre l'outil plus difficile à utiliser ? (et sinon, techniquement, je ne sais pas trop où est le code pour faire l’ajout dans le mw:Extension:WikiEditor). Cdlt, VIGNERON * discut. 13 avril 2016 à 17:52 (UTC)
- Merci pour le lien, j'ai pu ajouter le caractère à la liste (Voir mw:Extension:WikiEditor/Toolbar customization). Si ça peut servir à quelqu'un d'autre... Cdlt, R [CQ, ici W9GFO] 13 avril 2016 à 18:55 (UTC)
- Merci R, ça pourrait m'être utile. J'utilise le non-moins efficace copier-coller ! --Pikinez (d) 28 juin 2016 à 20:42 (UTC)
- Merci pour le lien, j'ai pu ajouter le caractère à la liste (Voir mw:Extension:WikiEditor/Toolbar customization). Si ça peut servir à quelqu'un d'autre... Cdlt, R [CQ, ici W9GFO] 13 avril 2016 à 18:55 (UTC)
Caractère inconnu[modifier]
Je bloque sur un caractère. Ici. (signalé par le modèle {{?}})--Hildepont (d) 4 mai 2016 à 08:23 (UTC)
- C'est probablement le signe de Saturne (♄). D'après w:♄, ce signe peut servir à désigner une plante ligneuse en botanique. Cordialement, Yann (d) 4 mai 2016 à 12:20 (UTC)
- Génial ! et merci beaucoup… Hildepont (d) 4 mai 2016 à 13:40 (UTC)
<math> vs. Unicode[modifier]
Bonjour, je suis partagé sur la méthode à adopter, votre avis m'intéresse.
Autant je comprends l'intérêt de l'usage de <math></math> pour les expressions mathématiques complexes, autant je me demande s'il est utile d'en abuser pour les expressions simples, comme dans la déclaration de monômes ou une simple opération (addition/soustraction). Il existe tout un tas de caractères Unicode(s) : Mathematical Alphanumeric Symbols, Mathematical operators and symbols in Unicode qui permettent, par exemple :
- de parler des points et (SVG 1.1ko + 1.2ko), en Unicode 𝐴 et 𝐵 (2×4 octets)
- de dire que (SVG 4.3ko), en Unicode 𝑀 = 𝜇𝑃 + 𝑧 (26 octets)
- etc…



{kind=link}
{kind=link}
{kind=link}
Si le wikicode <math></math> a désormais (ce n'était pas le cas avant) l'avantage d'insérer dans le code HTML d'une page les expressions mathématiques à l'intérieur d'une balise HTML <math></math> répondant à la norme W3C MathML, en plus de l'image SVG, lorsque cette option est activée dans les paramètres d'affichage, je trouve néanmoins que ça alourdit considérablement le poids d'un texte ou livre. Ainsi, à chaque fois que la lettre 𝐴 est inscrite avec <math></math>, ce n'est pas 4 octets que je télécharge mais environ 716 octets[1] + 1×1.1ko (SVG) , et même compressé je suis presque certain que ça reste plus lourd.
Quel est votre avis sur la question ?
Cordialement, R [CQ, ici W9GFO] 14 juin 2016 à 08:15 (UTC)
- Je suis tout à fait d'accord avec toi. D'autant plus que les caractères prennent très souvent, non pas quatre, mais à peine un ou deux octets puisqu'ils sont codés en UTF-8. BernardM (d) 15 juin 2016 à 18:48 (UTC)
- ↑ Code HTML de la lettre sans les espaces et retours à la ligne : <span><span class="mwe-math-mathml-inline mwe-math-mathml-a11y" style="display: none;"><math xmlns="http://www.w3.org/1998/Math/MathML"><semantics><mrow class="MJX-TeXAtom-ORD"><mstyle displaystyle="true" scriptlevel="0"><mi>A</mi><mspace width="thinmathspace"></mspace><mspace width="negativethinmathspace"></mspace></mstyle></mrow><annotation encoding="application/x-tex">{\displaystyle A}</annotation></semantics></math></span><img src="https://wikimedia.org/api/rest_v1/media/math/render/svg/b041434092d1f0042c2b4c7ab32ea84d462cb53e" class="mwe-math-fallback-image-inline" aria-hidden="true" style="vertical-align: -0.338ex; margin-right: -0.387ex; width:2.141ex; height:2.343ex;" alt="{\displaystyle A}"></span>
Double ligne verticale[modifier]
Bonjour, sur cette page on peut lire §4 à propos de la lettre A : « Comme note de musique, A servit à désigner, et il désigne encore aujourd’hui, pour les Allemands et les Anglais, le sixième ton de la gamme diatonique naturelle, auquel Gui d’Arezzo a donné le nom de la. || Écrit sur une partition, il indique l’alto. » S'agit-il du caractère « ‖ » (U+2016), qui, selon le Wiktionnaire anglophone servirait de marque de césure utilisé à la place du scratch comma, variante médiévale de la virgule ? Je ne l'ai pas trouvé dans la liste des caractères rares. R [CQ, ici W9GFO] 25 juin 2016 à 09:46 (UTC)
Symbole non identifié pour indiquer un numéro de note (?)[modifier]
Bonjour, je bute sur un symbole que je n'identifie pas et que je n'ai jamais vu (comme une croix lorraine surmontée d'un petit cercle) : à la toute fin du fac-similé de cette page. Quelqu'un connaît-il ce symbole, S.V.P. ? --Yland (d) 27 juin 2016 à 20:25 (UTC)
- Bonjour Yland, c'est vrai que le petit cercle au dessus laisse place au doute mais je dirais qu'il s'agit tout simplement d'un double obèle (‡), utilisé pour indiquer qu'il s'agit de la note n°3 ( * = note 1 ; † = note 2 ; ‡ = note 3 ). Ça tient plutôt la route, qu'en pensez-vous ? R [CQ, ici W9GFO] 28 juin 2016 à 05:50 (UTC)
- Super, ça colle très bien au contexte, je l'adopte. Merci R ! --Yland (d) 28 juin 2016 à 20:22 (UTC)
- Je rencontre les mêmes trois symboles dans les notes que Gilbert White ajoute à ses propres textes (sur la wikisource anglophone). --Zyephyrus (d) 29 juin 2016 à 21:47 (UTC)
- Et la boucle est bouclé, merci Zyephyrus pour ce parfait exemple (le tout sur une seule page), je propose que quelqu'un se charge de rajouter ce caractère à la liste des caractères rares, le simple obèle y est déjà présent. R [CQ, ici W9GFO] 30 juin 2016 à 13:01 (UTC)
- Je rencontre les mêmes trois symboles dans les notes que Gilbert White ajoute à ses propres textes (sur la wikisource anglophone). --Zyephyrus (d) 29 juin 2016 à 21:47 (UTC)
- Super, ça colle très bien au contexte, je l'adopte. Merci R ! --Yland (d) 28 juin 2016 à 20:22 (UTC)
La ligature de ct[modifier]
Bonjour. D’après l’aide sur les ligatures, utiliser la classe css « ligatures » devrait suffire à automatiser celles-ci. Or <span class="ligatures">actions</span> est rendu actions. Non seulement il n’y a pas la ligature sur « ct » mais de plus la police d’écriture n’est pas la même ! Une idée pour résoudre cette problématique ? C’est d’autant plus étonnant que sur mon poste Libertine est installé et que celle-ci gère bien cette ligature (cf p. 4 de ce manuel). --Psychoslave (d) 12 septembre 2016 à 12:24 (UTC)
- Bonjour. Je pense avoir un début de réponse, phe : complétera si besoin. La classe ligatures utilise la police Linux Libertine Regular qui gère une partie des ligatures : ct n'en fait pas partie, essayez d'écrire « action flic figé » dans ce formulaire et vous verrez des ligatures pour fl et fi mais pas pour ct. La police d'écriture, d'après la feuille de style, est définie sur Wikisource avec le nom WsLibertine (c'est, je pense, la raison pour laquelle vous ne la voyez pas malgré la police installée sur votre poste) et est accessible à l'adresse https://toolserver.org/~phe/fonts/LinLibertine_Re-4.7.5.ttf qui renvoie une erreur 404 (le fichier n'a pas été trouvé). Je dirais donc que c'est normal si ça ne fonctionne pas et c'est ce qui expliquerait également la taille des lettres plus grandes car font-size est fixée à 1.4em. Ça devrait pouvoir se régler rapidement, saut peut-être pour le ct. :-\ R [CQ, ici W9GFO] 12 septembre 2016 à 14:22 (UTC)
- Ok. Dans ce cas ce serait bien d’installer également libertine G qui selon cette documentation permet de faire ces ligatures. Est-ce qu’on peut préciser la police (
font-family) dans le style à même le texte ? Sinon il faudrait nécessairement créer une classe css spécifique, mais dans tout les cas ce serait intéressant. Je viens de voir qu’il y a un modèle:Ligat, qui parle de ct mais le rendu n’est pas bon sur mon poste.- Je viens d'installer et tester la police Linux Libertine G:hlig=1 et c'est vrai que ça fonctionne plutôt bien. Je ne suis pas contre, tant que ça reste facultatif. Qu'en pensent les autres ? R [CQ, ici W9GFO] 13 septembre 2016 à 08:46 (UTC)
- Facultatif de quelle façon ? En ce qui me concerne, plus l’utilisateur final a d’option, mieux c’est, mais il faut que l’ergonomie des options tienne la route. :) --Psychoslave (d) 13 septembre 2016 à 09:24 (UTC)
- Par facultatif je veux dire ne surtout pas utiliser le caractère Unicode
(U+E03D) en complément defont-family:"Linux Libertine G"oufont-family:"Linux Libertine Display"dans l'attribut style. Vous le voyez , d'autres probablement pas. Ça devrait pouvoir se gérer avec la classe CSS ligatures à l'aide de la propriétéfont-variant-ligatures: historical-ligatures;. R [CQ, ici W9GFO] 13 septembre 2016 à 11:56 (UTC)
- Par facultatif je veux dire ne surtout pas utiliser le caractère Unicode
- Facultatif de quelle façon ? En ce qui me concerne, plus l’utilisateur final a d’option, mieux c’est, mais il faut que l’ergonomie des options tienne la route. :) --Psychoslave (d) 13 septembre 2016 à 09:24 (UTC)
- Je viens d'installer et tester la police Linux Libertine G:hlig=1 et c'est vrai que ça fonctionne plutôt bien. Je ne suis pas contre, tant que ça reste facultatif. Qu'en pensent les autres ? R [CQ, ici W9GFO] 13 septembre 2016 à 08:46 (UTC)
- Ok. Dans ce cas ce serait bien d’installer également libertine G qui selon cette documentation permet de faire ces ligatures. Est-ce qu’on peut préciser la police (
⚔[modifier]
Bonjour, L’entrée wikt:fr:⚔ et l’article w:fr:⚔ viennent d’être créés. Merci à ceux qui reliront et complèteront ces deux pages. Merci aussi à ceux qui pourront indiquer si on trouve ce caractère « ⚔ » dans les textes réunis par Wikisource. Cordialement. Alphabeta (d) 16 octobre 2016 à 15:53 (UTC)
Sorte de H retrourné[modifier]
Il y a sur cette page (3e ligne), une sorte de H tourné à 90°. Ce caractère existe-t-il ? Ou bien faut-il appliquer une rotation à la lettre H ? --Hildepont (d) 26 décembre 2016 à 13:00 (UTC)
s en exposant ?[modifier]
Bonjour !
Il semblerait que sur la première ligne de cette page, le dernier s de secours ait bizarrement été placé en exposant. Je voulais d'une part savoir si c'était bien le cas ou s'il s'agit d'autre chose, et d'autre part si ça vaut le coup de le transcrire tel quel, dans la mesure où c'est la première fois que je rencontre un telle chose dans le livre et que ça pourrait tout aussi bien être un défaut d'imprimerie. Amitiés, --Jahl de Vautban (d) 30 décembre 2016 à 15:18 (UTC)
- Jahl de Vautban :
- pour moi c’est un défaut typographique --Hsarrazin (d) 30 décembre 2016 à 20:11 (UTC)
- Hsarrazin : du coup que dois-je en faire ? --Jahl de Vautban (d) 30 décembre 2016 à 21:04 (UTC)
- Jahl de Vautban : je rejoins l'avis de Hsarrazin. Je pense qu'il faut ignorer cette bizarrerie et écrire le mot normalement. Éventuellement, tu peux laisser une note sur la page de discussion.BernardM (d) 31 décembre 2016 à 09:25 (UTC)
- Jahl de Vautban : - une note en pdd avec
{{corrBandeau}}dans l’entête, et, si tu y tiens, un{{corr}}sur le mot concerné me semble bien --Hsarrazin (d) 31 décembre 2016 à 10:26 (UTC)
- Merci à vous deux ! J'ai ajouté un
{{corr}}sur le mot, mais il semblerait que le modèle n'accepte pas l'usage de balises. --Jahl de Vautban (d) 31 décembre 2016 à 12:27 (UTC)
- Merci à vous deux ! J'ai ajouté un
symbole d'abréviation des francs-maçons... ?[modifier]
Bonjour,
sur cette page et les suivantes, tous les acronymes francs-maçons sont écrits avec un astérisme entre chaque lettre, mais {{Astérisme}} me semble un peu gros, même en le réduisant, et provoque qui plus est un saut de ligne avant/après, systématiqueemnt. Par ailleurs, ⁂ reste encore très gros, et est-ce bien le symbole approprié ? (voir l’historique de la page pour mes essais).
Il me semble qu’il s’agit d’un signe signifiant pour les FM, qui devrait donc être reproduit…
Pour le moment, j’ai transcrit avec un point standard, mais ça me semblerait bien de pouvoir reproduire la graphie, y compris l’espèce de grand reectangle plat qui figure pour parler de la loge…
Quelqu’un aurait-il-une idée de génie pour faire ça proprement, et lisiblement, svp ? --Hsarrazin (d) 31 décembre 2016 à 10:39 (UTC)
- Bonjour, pour le rectangle on pourrait utiliser le caractère ▭ (WHITE RECTANGLE U+25AD), ça ne me semble pas inapproprié. Concernant le modèle
{{Astérisme}}, le saut de ligne est dû au fait qu'il se trouve dans un div (élément de type block), il faudrait peut-être créer un nouveau modèle ({{AstérismeAbbr}}) pour qu'il se trouve dans un span, conjugué à un font-size inférieur à 1em ça devrait être suffisant : « P⁂ ». Qu'en penses-tu ? R [CQ, ici W9GFO] 31 décembre 2016 à 12:16 (UTC)- Voir wikt:fr:Wiktionnaire:Wikidémie/août 2017#le trois points maçonnique (sujet n° 13 du mois wikt:fr:Wiktionnaire:Wikidémie/août 2017) : dans Wikipédia ainsi que dans le Wiktionnaire on se sert du caractère « ∴ » (cf. « wikt:fr:∴ » : Unicode : U+2234), en réutilisant un opérateur mathématique signifiant « par conséquent »… Alphabeta (d) 15 août 2017 à 13:17 (UTC)
Grec ancien : un spécialiste SVP[modifier]
Bonjour, faute de savoir où chercher je dépose mon message ici.
Sur cette page on peut lire en grec : « H`ρακλεὶα » et « O῾ λίϑος μαγνίτης » (le rouge est de moi). À quoi correspond l'apostrophe, à un esprit rude ? Dans ce cas pourquoi après le H et O et pas Ὴ et Ὸ ? Merci par avance pour votre aide. R [CQ, ici W9GFO] 24 février 2017 à 09:58 (UTC)
- Bonjour,
- En tant que semi-spécialiste (mais j'ai croisé pas mal de textes ici déjà) : oui, il s'agit bien d'esprits rudes. Pourquoi ? je ne pourrais pas l'affirmer avec certitude, mais je suppose qu'il s'agit d'un problème de caractères manquants. En tout cas, je serais pour transcrire Ὴ et Ὸ. --Acélan (d) 24 février 2017 à 13:34 (UTC)
- Acélan, je vais suivre ton conseil et faire comme toi où les mêmes mots sont présents. Pour le Ὸ je suis désormais certain car dans la version que tu as corrigée ὁ (en minuscule) est clairement visible, du coup peu de doute pour le Ὴ. Je ne sais toujours pas pourquoi les esprits sont placés après, étrange ! Je remarque cependant que tu as fais le choix de ne pas utiliser le modèle
{{corr}}!? Encore merci pour ton aide. R [CQ, ici W9GFO] 24 février 2017 à 19:45 (UTC) P.S. : je note également que tu as préféré θ à ϑ : c'est pareil tu vas me dire ! R [CQ, ici W9GFO] 24 février 2017 à 19:50 (UTC)
- Acélan, je vais suivre ton conseil et faire comme toi où les mêmes mots sont présents. Pour le Ὸ je suis désormais certain car dans la version que tu as corrigée ὁ (en minuscule) est clairement visible, du coup peu de doute pour le Ὴ. Je ne sais toujours pas pourquoi les esprits sont placés après, étrange ! Je remarque cependant que tu as fais le choix de ne pas utiliser le modèle
Décorations françaises[modifier]

{kind=link}
Bonjour,
Les typographes français disposaient autrefois de différents caractères pour symboliser les principales décorations françaises, telles que les Palmes académiques, la Légion d’honneur.
Ces symboles de décorations sont reproduits dans le Lexique des règles typographiques en usage à l’Imprimerie nationale (voir w:fr:LRTUIN : j’ai consulté un exemplaire imprimé en décembre 2011) page 64 sous la rubrique « Décorations ».
Il ne semble pas que ce symboles soient des caractères Unicode., mais des vérifications là-dessus restent à faire
Wikisource dispose-t-il de quelque chose pour reproduire ces symboles dans un texte ?
Merci d’avance. Alphabeta (d) 26 juillet 2017 à 17:10 (UTC)
- Voici un exemple : commons:file:Marie-Antoinette Belloc.jpg : dans cette carte de visite, deux symboles de décoration suivent le nom de « Madame Antoinette Belloc » (voir w:fr:Antoinette Belloc mais cet article encyclopédique est peut-être à vérifier). Alphabeta (d) 26 juillet 2017 à 17:22 (UTC)
- Ces deux symboles figurent dans la liste des glyphes à collecter… Donc je suppose que la seule solution serait de les mettre sous Commons pour pouvoir les insérer dans des textes. Seudo (d) 31 juillet 2017 à 12:41 (UTC)
Signe pourcent inversé[modifier]
Bonjour, J’ai trouvé ici un signe pourcent curieux, qui ressemble à ceci : 5 p. 0/0.
Je l’ai transcrit tel quel en imitant l’apparence avec du HTML. Avez-vous déjà rencontré ce signe ? Il ne semble pas exister dans Unicode. Le même ouvrage utile un signe plus classique là — du coup, je devrais peut-être plutôt le corriger. Seudo (d) 31 juillet 2017 à 13:02 (UTC)
- Seudo : en retombant sur un u interverti avec un n à l’envers, je me demande si ce n'est pas quelque chose de similaire qui est arrivé ici aussi (sauf que le composteur aurait fondu le % en miroir au lieu de le mettre à l’envers). Du coup la correction me semble la solution la plus logique. Cdlt, VIGNERON (d) 1 novembre 2017 à 15:42 (UTC)
- Pourtant, il ne s'agit pas exactement du miroir de la glyphe normale. Mais je suis d'accord, c’est très certainement une erreur. 5 %, c’est d’ailleurs bien le rapport entre la rente de 6 000 francs et le principal de 120 000 francs, mentionnés plus bas sur la page. C’est aussi le rendement normal du capital sur le très long terme, comme le savent ceux qui ont lu Balzac ou Piketty. Donc je corrige. Si quelqu’un trouvait l'édition de 1855 (je crois que cet ouvrage n'a eu que deux éditions)… Seudo (d) 1 novembre 2017 à 22:42 (UTC)
- Seudo : L’édition de 1855 est sur archive.org: https://archive.org/details/dictionnaireadmi00laza/page/650. Celle-ci utilise plutôt « 5 p. 100 ». --Moyogo (d)
- Merci Moyogo : Cela confirme que c’est une simple coquille dans la première édition. Peut-être le typographe composait-il le signe % avec trois caractères distincts, et cette fois il serait trompé dans l’ordre… Seudo (d) 3 février 2019 à 23:09 (UTC)
- Merci
- Pourtant, il ne s'agit pas exactement du miroir de la glyphe normale. Mais je suis d'accord, c’est très certainement une erreur. 5 %, c’est d’ailleurs bien le rapport entre la rente de 6 000 francs et le principal de 120 000 francs, mentionnés plus bas sur la page. C’est aussi le rendement normal du capital sur le très long terme, comme le savent ceux qui ont lu Balzac ou Piketty. Donc je corrige. Si quelqu’un trouvait l'édition de 1855 (je crois que cet ouvrage n'a eu que deux éditions)… Seudo (d) 1 novembre 2017 à 22:42 (UTC)
Caractère inconnu ?[modifier]
Bonjour,
Je ne reconnais pas le caractère que l'on trouve dans cette page. Cela vous dit-il quelque chose ? Éric (d) 12 septembre 2017 à 05:50 (UTC)
- Ca me fait penser à la marque des paragraphes (¶) et plus précisément à une de ses variantes : ❡ (voir l’image sur CURVED STEM PARAGRAPH SIGN ORNAMENT, même si l’apparence précise peut dépendre de la police de caractères). Seudo (d) 12 septembre 2017 à 07:10 (UTC)
- Ca me semble parfait, J'ai plus qu’a l’ajouter à mon clavier. seudo : Merci
- Ca me semble parfait, J'ai plus qu’a l’ajouter à mon clavier.
Légion d'honneur[modifier]
Bonjour,
Pour info, je viens de créer une image pour la Légion d'honneur et de l’utiliser dans le modèle {{X|légion d’honneur}} ce qui donne ![]() ainsi que sur la page Page:Deltil - Des abus de la saignée chez les animaux domestiques.djvu/34. Sauf contre-indications, je l'utiliserais partout où le caractère est présent (notamment les 95 thèses de Catégorie:Ouvrages issus du partenariat avec l’ENVT).
ainsi que sur la page Page:Deltil - Des abus de la saignée chez les animaux domestiques.djvu/34. Sauf contre-indications, je l'utiliserais partout où le caractère est présent (notamment les 95 thèses de Catégorie:Ouvrages issus du partenariat avec l’ENVT).
Cdlt, VIGNERON (d) 8 avril 2018 à 09:54 (UTC)
- VIGNERON : J'utilisais
 mais j’étais moyennement satisfait, car les traits était trop clairs. Je vais maintenant utiliser ton image. Merci ! Aristoi (d) 8 avril 2018 à 17:18 (UTC)
mais j’étais moyennement satisfait, car les traits était trop clairs. Je vais maintenant utiliser ton image. Merci ! Aristoi (d) 8 avril 2018 à 17:18 (UTC)
- Aristoi : plutôt que l’image elle-même, il me semble que l'idéal serait d'utiliser le modèle (ainsi on peut corriger et/ou améliorer tout les utilisations en même temps ; par exemple si un jour il y a un caractère Unicode spécifique, on pourra faire le remplacement en un clin d’œil). Cdlt, VIGNERON (d) 9 avril 2018 à 09:25 (UTC)
- Ca mériterait d'être encodé dans Unicode, y-a-til un inventaire accessible (et sans doute aussi d'autres ordres, notamment britanniques, allemands, russes, mais aussi des insignes et ordres militaires, religieux, mystiques, cabalistiques, confréries ?) Notez que l'usage des insignes et décorations officielles est sujet à des limitations de droit concernant leur usage, mais sans doute pas ceux qui ne sont plus en vigueur. On peut noter déjà la présence de nombreux symboles religieux et cabalistiques (symboles zodiacaux par exemple, piraterie, sorcellerie, occultisme, cercles d'initiés) et après tout il y a aussi des emojis représentant des métiers ou fonctions publiques ou réglementées (police, justice, éducation). De même les symboles et émojis pour les drapeaux nationaux ou régionaux. Le symbole a juste vocation à être identifiable mais pas une représentation fidèle au plan artistique ou artisanal et les couleurs n'ont pas vocation à être exactement fidèles. On s'abstiendra je pense des signes politiques mais déjà nombre de groupes politiques ont fait usage de signes religieux (dont pas mal de croix, croissants, roues, symboles d'astres, animaux) qu'on retrouve aussi dans drapeaux et armoiries (Unicode ne représente pas la forme exacte du glyphe, ni ses couleurs exactes, mais suffisamment de distinctions pour que la sémantique soit préservée et non confondue avec d'autres. On a pas mal de symboles aussi pour les croix et astérisques. Des signes comme les palmes, croix d'honneur, rubans, écharpes, pompons, rosettes seraient bienvenus, on a déjà certains écussons. — Verdy_p (d) 6 octobre 2019 à 22:43 (UTC)
- Verdy p : oui, la demande est déjà en cours (cela ne sera certainement pas encore pour Unicode 13.0 par contre). Cdlt VIGNERON (d) 9 octobre 2019 à 15:29 (UTC)
Caractère grec mystérieux[modifier]
Bonjour,
.jpg)
Habituellement j’essaie de transcrire moi-même les caractères grecs même si je n’en suis pas du tout un spécialiste, mais cette fois je ne parviens vraiment pas à déchiffrer le mot présent sur Page:Ripa - Iconologie - 1643.pdf/339. D'après le Wiktionnaire, le terme grec correspondant au latin Cinclus est κίγκλος, mais les caractères paraissent différents ici, ou alors les glyphes sont vraiment inhabituels, notamment juste avant le ς final. Quelqu’un aurait-il une idée ? Seudo (d) 27 mars 2020 à 10:17 (UTC)
- Yland (d · c · b) y lit Κιϰηρὸς. Je lui ferai confiance ! Seudo (d) 27 mars 2020 à 21:51 (UTC)
- Bonjour Seudo : Les 3 dernières lettres sont une ligature pour "ros". Cette graphie qui utilise des ligatures et abréviations du grec ancien vient du moyen-âge et de la Renaissance. À partir de l’avénement de l’imprimerie, on commence à voir notre transcription moderne (sans ligature ni abréviation). Cf. Ligatures de l'alphabet grec. Cordialement, --Yland (d) 28 mars 2020 à 09:57 (UTC)
- Merci pour l’explication. J’avais pensé à un rhô arrondi (ϱ), mais cela ressemble en effet à une ligature. Seudo (d) 28 mars 2020 à 11:34 (UTC)
- Un peu tard, mais la graphie Κιϰηρὸς utilise le symbole technique ϰ, qui a une forme unique de kappa cursif. Il faudrait plutôt utiliser la lettre kappa κ, qui a plusieurs formes dont cette forme-ci selon le style, donc la graphie Κικηρὸς. ---Moyogo (d) 22 août 2020 à 14:17 (UTC)
- En effet, cela me paraît convaincant. J'ai fait la correction. Seudo (d) 22 août 2020 à 19:21 (UTC)
- Un peu tard, mais la graphie Κιϰηρὸς utilise le symbole technique ϰ, qui a une forme unique de kappa cursif. Il faudrait plutôt utiliser la lettre kappa κ, qui a plusieurs formes dont cette forme-ci selon le style, donc la graphie Κικηρὸς. ---Moyogo (d) 22 août 2020 à 14:17 (UTC)
- Merci pour l’explication. J’avais pensé à un rhô arrondi (ϱ), mais cela ressemble en effet à une ligature. Seudo (d) 28 mars 2020 à 11:34 (UTC)
- Bonjour
Demande de confirmation de la retranscription de πρεσβύτεροι en πρεςϐύτεροι[modifier]
Salut ! Décidément Grammaire de Denys de Thrace me réserve bien des surprises. ![]() Page 10 apparaît le mot qui me semble correspondre à πρεσβύτεροι, mais avec des variantes graphiques pour certaines lettres qui me semble donc plutôt coïncider avec πρεςϐύτεροι. Bon déjà je m’étonne de la présence de cette forme alternative de sigma en plein milieu d’un mot, mais en préservant uniquement cette variante de lettre, donc en transcrivant ''πρεςβύτεροι, la forme renvoie bien des résultats par des moteurs de recherche généraliste, et même un usage sur la wikipédia germanophone. Ceci étant, c’est surtout le bêta qui interrogation. La forme graphique la plus proche de l’originale me semble être le bêta bouclé « ϐ », ce qui donnerait πρεςϐύτεροι. Cela étant, en fonction des polices d’écritures, le bêta bouclé ne ressemble pas forcément à ce qui est présent dans le facsimilé : les boucles ne s’y touche pas, alors que c’est le cas dans la police utilisé par défaut sur Wikisource. De plus je n’ai trouvé aucune occurrence ayant cette exacte graphie par moteur de recherche. Cela dit je constate que les moteurs de recherche et même la recherche dans une page n’a aucune difficulté à trouver toutes les alternatives graphique à partir de l’une d’elle, merci unicode ! Bon, mes recherches m’ont quand même permis de découvrir, via Variante contextuelle sur la Wikipédia francophone que l’usage du bêta bouclé est une originalité des philologues français – pourquoi faire comme tout le monde quand on peut se démarquer…
Page 10 apparaît le mot qui me semble correspondre à πρεσβύτεροι, mais avec des variantes graphiques pour certaines lettres qui me semble donc plutôt coïncider avec πρεςϐύτεροι. Bon déjà je m’étonne de la présence de cette forme alternative de sigma en plein milieu d’un mot, mais en préservant uniquement cette variante de lettre, donc en transcrivant ''πρεςβύτεροι, la forme renvoie bien des résultats par des moteurs de recherche généraliste, et même un usage sur la wikipédia germanophone. Ceci étant, c’est surtout le bêta qui interrogation. La forme graphique la plus proche de l’originale me semble être le bêta bouclé « ϐ », ce qui donnerait πρεςϐύτεροι. Cela étant, en fonction des polices d’écritures, le bêta bouclé ne ressemble pas forcément à ce qui est présent dans le facsimilé : les boucles ne s’y touche pas, alors que c’est le cas dans la police utilisé par défaut sur Wikisource. De plus je n’ai trouvé aucune occurrence ayant cette exacte graphie par moteur de recherche. Cela dit je constate que les moteurs de recherche et même la recherche dans une page n’a aucune difficulté à trouver toutes les alternatives graphique à partir de l’une d’elle, merci unicode ! Bon, mes recherches m’ont quand même permis de découvrir, via Variante contextuelle sur la Wikipédia francophone que l’usage du bêta bouclé est une originalité des philologues français – pourquoi faire comme tout le monde quand on peut se démarquer… ![]() . Donc πρεςϐύτεροι me semble correct, mais par acquis de conscience, il m’a parut préférable de demander confirmation ici. Il faudra aussi que je regarde pour modifier la police utilisé pour le rendu du livre, maintenant qu’il y a une CSS par livre ça paraît tout à fait jouable de manière assez triviale. --Psychoslave (d) 18 avril 2021 à 08:57 (UTC)
. Donc πρεςϐύτεροι me semble correct, mais par acquis de conscience, il m’a parut préférable de demander confirmation ici. Il faudra aussi que je regarde pour modifier la police utilisé pour le rendu du livre, maintenant qu’il y a une CSS par livre ça paraît tout à fait jouable de manière assez triviale. --Psychoslave (d) 18 avril 2021 à 08:57 (UTC)
- Psychoslave : Vous faites bien de demander ! Votre première idée, utiliser le bêta initial β est la bonne. Ce sont deux formes possibles, la première imitée de l’écriture manuscrite, la seconde plus typique des imprimeries, pour la même lettre (de même que, pour nous, selon la fonte, le g peut avoir une boucle fermée ou ouverte, ou le a avoir ou non une hampe supérieure : par exemple : g/g, a/a : ce n’est pas pour autant qu’on change de caractère pour les transcrire), interchangeables partout dans le monde, sauf en France jusqu’au xxe siècle, où l’on n’utilisait le bêta initial qu’en début de mot ; mais en typographie grecque numérique, seul β existe : en Unicode, l’autre caractère n’est pas une lettre grecque, mais un symbole, réservé à des utilisations essentiellement scientifiques. Il en est de même des couples ε/ϵ, θ/ϑ, κ/ϰ, π/ϖ, ρ/ϱ, φ/ϕ : seul le premier caractère doit être utilisé, le second étant un symbole et non une lettre (faites attention : selon la police, les variantes graphiques peuvent être affectées différemment à la lettre ou au symbole : remarquez notamment comment la lettre et le symbole φ/ϕ s’échangent leur forme entre la police à chasse fixe utilisée par le code, et la police sans empattements utilisée dans l’affichage principal !). Voyez le standard Unicode, page 303.
- Pour le sigma, effectivement on attendrait un sigma initial/médian σ, et non un sigma final ς. En relisant la page 9, j’ai vu que l’ouvrier-compositeur avait confondu un accent aigu avec un esprit doux ; je pense donc que l’ouvrier n’avait pas de grandes connaissances en grec, et qu’il s’agit d’une coquille. J’utiliserais donc ici
{{corr|πρεςβύτεροι|πρεσβύτεροι}}, avec éventuellement un message expliquant la correction en page de Discussion. - Je ne sais pas à quel point vous avez des connaissances en grec ; mais pour demander une relecture par des contributeurs connaissant bien la langue (entre autres Jahl de Vautban et moi-même, qui vous avons déjà répondu ), vous pouvez utiliser le modèle
{{grec}}: en mettant{{grec|πρεςϐύτεροι}}à l’endroit du mot grec, la page est classée dans Catégorie:Mots manquants en grec ancien, et régulièrement les contributeurs lisant couramment le grec viennent en faire le tour. Cf. mon message sur le Scriptorium, à propos de l’arménien. - Enfin, pour la police du livre, je ne saurais trop vous recommander de laisser la police par défaut, pour la cohérence graphique du site, pour l’adaptabilité selon les différents dispositifs de lecture, navigateurs et thèmes utilisés par les Wikisourciens ou par les lecteurs, et pour le rendu le plus large possible des caractères Unicode (il ne sera pas dit que votre lecteur disposera de la bonne police, un Didot, je présume ici, ni que cette police rendra tous les caractères grecs et arméniens ; alors que le Arial, le Corbel ou le Times utilisés par les différents thèmes Wikisource, si ; enfin, il faut que le lecteur sur liseuse soit autorisé à choisir la police qu’il veut sur sa liseuse, choix que vous lui enlevez en imposant la police dans la feuille de style). Par contre, vous devez pouvoir changer la police d’écriture utilisée par
.textquand vous êtes connecté en modifiant votre page common.css ; vous serez seul à voir ce changement, et tout contributeur peut faire le même s’il le veut. — ElioPrrl (d) 18 avril 2021 à 14:12 (UTC)- Salut, après lecture des explications (merci), je reste interrogatif : est-ce que le passage dans l’article Wikipédia est erroné ?
Dans la tradition philologique française exclusivement, le bêta, seulement en minuscule, ne se trace β qu'en début de mot. Ailleurs, il prend la forme bouclée ϐ : ΒΑΡΒΑΡΟΣ / βάρϐαρος b[[Auteur:|Auteur:]]árbaros, « barbare ».
- Le même article indique en infobox que ϐ est une graphie médiane (rare). De plus, je constate que d’après la documentation officielle de Unicode pour le plan de point de code concerné, certes le bêta en question correspond au symbole comme tu le soulignes avec raison, mais encore qu’il correspond aussi au bêta courbé, bêta bouclé.
- Aussi, sans m’avancer sur les compétences générales de la personne qui s’est occupée de la composition de l’ouvrage, avec les données ci-dessous il semblerait que le ϐ était légitime dans ce contexte et que le caractère unicode U+03D0 soit tout à fait idoine pour le retranscire ici. Bien sûr des détails auront pu m’échapper, et ou des informations me manquer, tout complément est bienvenu.
- Je met de côté les aspects mise en forme pour le moment, constatant que le niveau de fidélité que je souhaites mettre en œuvre n’est pas accueilli avec énormément de bienveillance en espace page. Ma volonté d’excellence sur ce point pourra toujours être satisfaite par ailleurs ultérieurement. Il paraît plus pertinent de concentrer les efforts sur les aspects consensuels. --Psychoslave (d) 19 avril 2021 à 20:32 (UTC)
- PS : Voyez le message de Moyogo dans le fil précédent à propos du kappa, qui va dans la même direction que le mien à propos du bêta. — ElioPrrl (d) 18 avril 2021 à 14:22 (UTC)
- Je me suis mal fait comprendre. Le caractère beta médian existe, il a la forme suivante : ϐ, et c’est bien une forme possible de β, utilisée selon la fonte : tout comme, dans l’alphabet latin, le ɑ peut être une forme de la lettre a, selon la fonte ou la position. Que le typographe l’ait utilisé en cette position est tout à fait normal en typographie française.
- Par contre, le caractère ϐ d’Unicode n’est pas une lettre grecque, ce n’est pas la lettre beta médian ; et la lettre beta médian n’a pas été créée dans Unicode, et ne le sera probablement jamais, car le remplacement des betas initiaux par des betas médians est une histoire de « contextual alternates », géré non par Unicode, mais par la police Opentype utilisée. [Parenthèse : j’ai dit que la seule exception était le sigma ; en réalité, ce n’en est pas une : car il y a des moments où le remplacement de σ par ς ou inversement change le sens — ainsi, « φιλοσ. » est l’abréviation du mot philosophos ; tandis que « φιλος. » est le mot philos suivit d’un point ; par conséquent un algorithme ne peut pas faire seul la substitution. Par contre, chacun des couples de ductus ci-dessus est composé de caractères interchangeables, gérables par un algorithme s’il sont utilisés comme variantes contextuelles.]
- Ce caractère Unicode est le symbole beta médian, qui a la même forme, mais qui est un caractère mathématique ; tout comme dans Unicode sont fournis des symboles ayant les mêmes formes que les lettres de l’alphabet, mais qui sont réservés à un usage mathématique. C’est comme si vous remplaciez les a par des ɑ partout parce que telle est leur forme dans le fac-similé : mais alors vous ne retranscrivez pas le même texte, puisque vous utiliseriez une lettre, l’alpha latin, qui a un sens dans l’API et dans certaines langues africaines, mais qui n’est pas un A minuscule. Même forme, mais pas même sens. — ElioPrrl (d) 19 avril 2021 à 20:50 (UTC)
- Je recopie le passage du standard Unicode qui prescrit cela : « In contrast, U+03D0 greek beta symbol, [suit tout la liste de variantes ci-dessus] should be used only in mathematical formulas—never in Greek text. If positional or other shape differences are desired for these characters, they should be implemented by a font or rendering engine. » — ElioPrrl (d) 19 avril 2021 à 21:26 (UTC)
- La section de l’article w:Variante contextuelle#L’alphabet grec est problématique. Elle mélange plusieurs choses qui sont facilement confondues, les codages informatiques ne sont pas parfaits et créé facilement ce genre de confusion. On peut noter par exemple que dans la première phrase, « On trouve en grec deux variantes contextuelles : sigma (σ/ς/c ; Σ/C) et bêta (β/ϐ). D'autres variantes dites « libres » existent aussi pour delta (δ/?), epsilon (ε/ϵ), kappa (κ/ϰ), thêta (θ/ϑ), xi (ξ/?), pi (π/ϖ), rhô (ρ/ϱ) et phi (φ/ϕ) en minuscule, ainsi que pour upsilon (Υ/ϒ) en capitale ; », des points intérrogation sont présent là où il n’y a pas de caractères codés avec la forme désirée. En gros ϐ, ϑ, ϒ, ϕ, ϰ, ϱ, ϴ, ϵ, ϶ sont sensés être utilisé uniquement comme symboles techniques comme indiqué à la page 303 du standard Unicode cité par ElioPrrl ci-dessus. Cependant ς est bien utilisé comme variante positionnelle du σ dans l’écriture du grec, mais c’est plutôt pour des raisons historiques de codage informatique ; quant au sigma lunaire Ϲ et ϲ (mis à part le fait que les caractères latins C et c soit utilisés dans la phrase), ils sont utilisés dans d’anciens et texte en concurrence avec Σ et ς ; pour ϖ U+03D6, Unicode ne limite pas son usage aux notations techniques mais indique que c’est une variante du pi. On peut donc se demander pourquoi certains sont des variantes limitées à l’usage technique et les autres non. Yannis Haralambous clarifie cette différence dans Guidelines and Suggested Amendments to the Greek Unicode Tables (2002) :
- Note that we did not include U+03D6 GREEK PI SYMBOL in the rule because its situation is not very clear: it maybe used in Greek text, even if the typographical conventions and the semantics it may carry are unclear.
On the other hand, it is perfectly clear that U+03F2 GREEK LUNATE SIGMA SYMBOL and its uppercase version (which we propose for insertion in the Unicode standard, see§3.1) are variant versions of U+03C2 GREEK SMALL LETTER FINAL SIGMA, U+03C3 GREEK SMALL LETTER SIGMA and U+03A3 GREEK CAPITAL LETTER SIGMA with special semantics, namely the ones of context-free sigma letters, both uppercase and lowercase.
- Note that we did not include U+03D6 GREEK PI SYMBOL in the rule because its situation is not very clear: it maybe used in Greek text, even if the typographical conventions and the semantics it may carry are unclear.
- La raison est donc que Ϲ, ϲ et ϖ ont ou peuvent avoir une différence sématique et non pas uniquement stylistique. --Moyogo (d) 27 avril 2021 à 10:36 (UTC)
- En relisant Sigma: final vs. non-final de Nick Nicholas, on pourrait avoir des raisons d’utiliser ϐ. Par exemple, pour le sigma, une police d’écriture ne peut pas faire la différence entre le sigma final en fin de mot et suivi d’un point en fin de phrase « [...] φιλόσοφος. » et un sigma médial en fin d’abréviation « Φιλόσ. ». Nicholas donne d’autres exemples de cas où le caractère propre au sigma final permet de gérer la règle d’orthographe sans trop de complexité. Pour l’usage du ϐ dans la tradition française, c’est donc à voir, mais vu que ce n’est pas vraiment une règle d’orthographe grecque mais plutôt une habitude c’est moins justifiable. --Moyogo (d) 27 avril 2021 à 13:43 (UTC)
Caractères et glyphes difficiles à produire[modifier]
Bonjour, Je tente de corriger le Dictionnaire Étymologique du grec (Boisaq) et je dois dire que je rencontre de sérieuses difficultés pour écrire et des fois reconnaître certains caractères. J'aurai besoin d'aide pour faire le tour des caractères exotiques rencontrés. Le dernier blocage que j'ai (et je suis au tout début :-) ) est de transcrire un n diacrité à la fois d'un accent circonflexe par dessus et d'un rond souscrit. Et deux espace/deux caractères plus loin se trouve un caractère qui ressemble à un n mais dont la fin boucle sur elle-même.
Jetez s'il vous plaît in œil et si quelqu'un a des tuyaux ce sera une aide très précieuse. Avec mes remerciements anticipés.— Le message qui précède, non signé, a été déposé par VilainHilare (discuter), le 22 octobre 2021 à 22:43
- Bonjour @VilainHilare, je pense que la majorité de ces caractères n'ont pas leur équivalent unicode. Il faudra passer par d'autres construction. En absence de lien vers la page pour vérifier, je me base sur vos descriptions. Le premier charactère que vous décrivez pourrait être
n̥̂, obtenu avec la syntaxen̥̂; le secondꬻ(qui lui a son équivalent unicode et existe comme tel). Pour les combinaisons de diacritiques vous pouvez aller sur ce site, cliquer sur les caractères qui vous intéressent et reporter la première ligne du champs Entité HTML (je ne suis peut-être pas très clair, dites-le moi si c'est le cas). Dans tous les cas il faut bien respecter les alphabets et ne pas interchanger les lettres grecques et latines. Sacré projet en tout cas, j'espère le voir abouti ! --Jahl de Vautban (d) 23 octobre 2021 à 07:58 (UTC)
Bonjour ![]() VilainHilare : Je n’ai pas d’assez bons yeux pour voir exactement le caractère que vous cherchez. Toutefois, si d’autres caractères vous pose problème il existe voici sur wikipédia des pages où vous pouvez retrouver des caractères spéciaux concernant chaque lettre. En bas de chacune de ces pages, il y a une la boîte déroulante commençant par : "variante de lettre … " ; pour certaines pages il y a en plus : "Tableau des codes des différentes variations de la lettre… "
VilainHilare : Je n’ai pas d’assez bons yeux pour voir exactement le caractère que vous cherchez. Toutefois, si d’autres caractères vous pose problème il existe voici sur wikipédia des pages où vous pouvez retrouver des caractères spéciaux concernant chaque lettre. En bas de chacune de ces pages, il y a une la boîte déroulante commençant par : "variante de lettre … " ; pour certaines pages il y a en plus : "Tableau des codes des différentes variations de la lettre… "
Lettres
A — B — C — D — E — F — G — H — I — J — K — L — M — N — O — P — Q — R — S — T — U — V — W — X — Y — Z
Le mieux serait que vous recopiez ce petit encart sur votre page pour le retrouver facilement ou alors de consulter ma page utilisateur : boite déroulante : "Utilitaires"
cordialement,
--Le ciel est par dessus le toit Parloir 23 octobre 2021 à 08:33 (UTC)
- Merci Beaucoup à @Jahl de Vautban@Le ciel est par dessus le toit
- Votre aide est vraiment précieuse. Il se trouve que je suis débutant et je cherchais à contribuer sur un sujet facile mais le hasard m'a fait tomber sur ce dictionnaire et ça a été le coup de foudre. Je vais avancer donc à pas de tortue en vous sollicitant pas mal au début sans doute. Encore merci. VilainHilare (d) 25 octobre 2021 à 16:33 (UTC)
Bonjour,
J'aurais besoin de produire un iota minuscule chapeauté d'un macron avec accent (oxie?). Est ce que la construction ci-après est satisfaisante : ῑ´
Le caractère se trouve à la huitième ligne de Dans https://fr.wikisource.org/wiki/Page:Boisacq_-_Dictionnaire_etymologique_grec_-_1916.djvu/15— Le message qui précède, non signé, a été déposé par VilainHilare (discuter), le 29 octobre 2021 à 23:29
- Bonjour @VilainHilare. L'idée était bonne, mais vous avez sans doute remarqué que les deux diacritiques ne se superposent pas. C'est parce que l'accent aigu grec n'est pas considéré (bizarrement) comme une diacritique, pas plus que l'accent aigu tout court d'ailleurs ; il faut aller chercher le code du diacritique accent aigu
́pour obtenir l'effet voulu : ῑ́. Dans le cas où il y a plusieurs diacritiques, j'aurai personnellement tendance à les mettre tous au même régime et à ne pas prendre une lettre déjà "diacritiquée" comme base, mais sans doute que ça impactera peu le résultat final. --Jahl de Vautban (d) 30 octobre 2021 à 06:27 (UTC) - Merci Jahl,
- Grâce à vos conseils j'avance. D'ailleurs, j'ai de nouveau une demande d'aide :-).
- Je suis sur le mots grec αδύς avec un α initial chapeauté d'une sorte de hamza arabe. Quel peut être ce diacritique qui ressemble à une hamza et comment produire la lettre α avec ce diacritique?
- C'est à la ligne 15 du la la page https://fr.wikisource.org/wiki/Page:Boisacq_-_Dictionnaire_etymologique_grec_-_1916.djvu/15
- Merci d'avance VilainHilare (d) 30 octobre 2021 à 12:30 (UTC)
- VilainHilare : j'ai plutôt l'impression qu'il s'agit d'un alpha avec macron et esprit rude : ἁ̄ .--Jahl de Vautban (d) 30 octobre 2021 à 12:40 (UTC)
- C'est possible mais à l’œil même sur archive.org, je vois le signe macron et l'esprit liés. Comme je suis très débutant en grec, je me pose sans doute quelquefois des questions sans objet et je doute là où un helléniste verra tout de suite de quoi il s'agit.
- Je commence déjà à m’initier en autodidacte au grec ancien pour pouvoir avancer plus tard en connaissance de cause.
- Merci encore et à bientôt pour mes prochaines questions. VilainHilare (d) 30 octobre 2021 à 12:57 (UTC)
- VilainHilare : avoir des bases de grec vous simplifiera grandement la vie. En cas de doute face à une graphie, et même d'ailleurs dans votre apprentissage du grec, je vous recommande l'outil Eulexis qui vous permettra de rapidement identifier un mot, avec son accent et son éventuel esprit. ἁδύς ayant nécessairement un esprit rude, on peut facilement en déduire que le trait est un macron. --Jahl de Vautban (d) 31 octobre 2021 à 13:44 (UTC)
- La copie sur Commons est beaucoup trop basse définition. Il vaut mieux vérifier avec la copie sur Archive.org ([11]). Ce genre de document est plein de petit piège si on ne fait pas attention ou si on ne connait pas les spécifités des codages informatiques. Comme mentionné auparavant les caractères d’accents diacritiques peuvent être utilisés ici, mais dans le bon ordre bien sûr. Il faut évité de confondre ά et ἀ ou encore ὰ et ἁ. Il faut aussi savoir que ce qui ressemble à une brève inversée sur η̑ ou ι̑ est en fait un perispomeni qui a la forme d’une brève inversée ou parfois d’un tilde, donc il faut plutôt utiliser ῆ et ῖ même s’ils n’ont pas le perispomeni avec la forme d’une brève inversée dans certaines polices de caractères. Le n̥̂ semble aussi plutôt être un n̥̑ (avec une brève inversée au lieu d’un accent circonflexe). Dans tout les cas, il vaut mieux configurer son navigateur web pour qu’il affiche le texte de modification avec une police qui fait clairement la distinction entre toutes ces diacritiques. J’ai modifié la page en relation avec ses notes, avec le Ϝ minuscule en plus. Bonne chance ! --Moyogo (d) 15 novembre 2021 à 15:02 (UTC)
J'ai un problème avec Raoul...[modifier]
Non, je ne suis pas celle que vous croyez :-)
Le Raoul en question est celui de la page 152 ou le typographe, pour marquer que le mot « Raoul » ne fait qu'une syllabe, l'a souligné par une « parenthèse courbe » sur les trois lettres. Genre « Raoul » sauf que c'est courbe. Genre « Ra͜oul », sauf que le « diacritique brève souscrite » qu'est le « ͜ » porte ici sur trois lettres et non deux. Et quand on en met deux, ça donne « Ra͜o͜ul », ce qui n'est pas esthétiquement acceptable. Ou mettre le second au-dessus pour avoir « Ra͜o͡ul » (diacritique double brève renversée) voire « Ra͜o͝ul » (diacritique double brève) ?
J'aurais tendance à mettre « Ra͜o͝ul » comme à la fois esthétique et logique - après tout, c'est bien un ŭ (u bref) que l'auteur veut représenter phonétiquement, donc « o͝u » n'est pas idiot ici, et il veut marquer qu'il s'agit d'une syllabe unique, donc la liaison par le bas rend bien l'idée.
Choix éditorial qui sera évidemment applicable sur les autres exemples, mais je préfère sonder avant. Qu'en pensent les experts? (codage unicode en HTML= w͜w et w͝w) Micheletb (d) 1 décembre 2021 à 14:30 (UTC)
- Est-ce que Raoul vous conviendrait ? — ElioPrrl (d) 1 décembre 2021 à 22:00 (UTC)
- Merci ElioPrrl : Je penche plutôt pour une courbure plus ronde à Raoul mais l'idée est bonne. Micheletb (d) 2 décembre 2021 à 05:13 (UTC)
- Merci
u̯ Un u avec une brève inversée souscrite ...placé haut[modifier]
Bonjour tous, Dans le dictionnaire étymologique grec de Boisacq https://fr.wikisource.org/wiki/Page:Boisacq_-_Dictionnaire_etymologique_grec_-_1916.djvu/17 , il y a un caractère que je ne sais pas produire. Il s'agit d'un u avec une brève inversée souscrite mais placé haut. Par exemple, il y dans le texte le mot gu̯u̯-ā dont le premier u̯ est placé nettement plus haut que l'autre. On trouve plusieurs occurrence de ce caractère à partir de la 4 ieme ligne en partant de la fin de la page XIII. Comment reproduire ce caractère ? Et accessoirement, est-ce que quelqu'un saurait comment il se prononoce ? — Le message qui précède, non signé, a été déposé par VilainHilare (discuter), le 27 janvier 2022 à 12:42
- En théorie, on peut utilisé la lettre modificative minuscule u avec le signe diacritique brève inversée « ᵘ̯ », donnant par exemple « gᵘ̯ᵘ̯-ā ». Cependant, on peut aussi retrouver le formatage <sup> mettant en exposant la lettre minuscule u avec le signe diacritique brève inversée « u̯ », « gu̯u̯-ā ». Dans les deux cas, la diacritique est un caractère séparé. La première option avec la lettre modificative est sémantiquement plus précise et est conservée lorsque le formatage stylistique est perdu (par exemple lors de certains copiés-collés), par contre toutes les polices de caractères ne gèrent pas nécessairement le positionnement du signe diacritique sous cette lettre modificative. --Moyogo (d) 27 janvier 2022 à 18:37 (UTC)
- Dans les deux cas, la taille de la lettre est aussi un problème de style. Dans certains ouvrages elle est plus petite que les lettres normales et dans ceux comme celui-ci elle a la même taille mais reste élevée. Sémantiquement cela ne fait aucune différence. --Moyogo (d) 27 janvier 2022 à 18:45 (UTC)
K barré[modifier]
Bonjour,
Il existe en breton une lettre « K barré » (abréviation de "ker") mais pendant longtemps, il n'y a pas eu de plomb pour ce caractère.
Du coup, pour la page Page:Catalogue raisonné du Musée d’Archéologie et de Céramique.djvu/275 (dans la seconde transcription d'inscription), vaut-il mieux mettre k/goet (ce que j'ai fait et qui est la transcription la plus courante) ou vaut-il mieux utilisé le caractère Unicode dédié : ꝃgoet ? Les deux seraient corrects mais j'ai du mal à choisir entre les deux (et chez moi, le modèle {{sc}} ne fonctionne pas pour ce caractère :/ d'où mon choix de laisser k/ pour le moment).
Cdlt, VIGNERON en résidence (d) 12 décembre 2022 à 14:24 (UTC)
- VIGNERON en résidence : La typographie du facsimile utilise K/ et l’inscription originale utilise sans doute Ꝃ. J’aurais utilisé ꝃ. --Moyogo (d) 20 mai 2023 à 17:55 (UTC)
Poussé musical[modifier]
Bonjour,
J'aurais besoin du symbole pour représenter le poussé en musique (voir ici). Savez vous s'il existe un symbole équivalent pour cela ? Pourrait-il être inclut dans le modèle {{musique}} ?
Merci d'avance, et bonne journée à vous ! Tambuccoriel (d) 10 mars 2023 à 11:07 (UTC)
- Tambuccoriel : voilà : 𝆪 (et 𝆫 pour le tiré).
- Pas sûr qu'il faille vraiment encore utiliser le modèle musique (Internet Explorer c'est maintenant moins de 1 % des navigateurs).
- Cdlt, VIGNERON (d) 10 mars 2023 à 19:02 (UTC)
- @VIGNERON Je vois effectivement bien les symboles avec Firefox, mais @Tambuccoriel, qui apparemment utilise Safari, voit des carrés, donc le problème ne vient sans doute pas uniquement d'IE ? Acélan (d) 10 mars 2023 à 22:13 (UTC)
- J'ai essayé sous Safari et sous Opéra, et aucun des deux navigateurs ne m'affiche le symbole, malheureusement… Tambuccoriel (d) 10 mars 2023 à 22:14 (UTC)
- Acélan et Tambuccoriel : ah autant pour moi, dans ce cas, je laisse quelqu'un faire l'intégration dans le modèle (et dans l’idéal, mettre aussi à jour la doc dudit modèle). Cdlt, VIGNERON (d) 11 mars 2023 à 07:49 (UTC)
- J'ai essayé sous Safari et sous Opéra, et aucun des deux navigateurs ne m'affiche le symbole, malheureusement… Tambuccoriel (d) 10 mars 2023 à 22:14 (UTC)
- @VIGNERON Je vois effectivement bien les symboles avec Firefox, mais @Tambuccoriel, qui apparemment utilise Safari, voit des carrés, donc le problème ne vient sans doute pas uniquement d'IE ? Acélan (d) 10 mars 2023 à 22:13 (UTC)
police cursive[modifier]
C'est pareil à la question Gothique: dans le livre Le Pantcha-Tantra ou les cinq ruses il y a un mot (Sloca) écrit en cursive sur plusiers pages. En 2014 fut créé le modèle Sloca pour ce mot. Je trouve que serait plus simple indiquer les polices dans le paramètre "ff" du modèle centré comme ça: {{centré|Sloca.|fs=140%|ff=Parisienne,'Segoe script'}}. J'ai étudié le modèle de WS anglophone cursive : de tous les polices utilisées seulement Segoe Script fonctionné (parce que je la tiens instalée?). J'ai trouvé la police Parisienne sur Google webfonts et c'est parfait, mais elle fonctionne seulement si je l'installe (Windows 10), différemment de la police du modèle Gothique (aussi utilisé dans ce livre), malgré la modification de préférence indiquée (qui marche pour moi au modèle Gothique). Voir Page:Dubois - Le Pantcha-Tantra ou les cinq ruses.djvu/57 Le Pantcha-Tantra ou les cinq ruses/Exposition. Il y a des autres pages qui pourraient l'utiliser : Page:Dubois - Le Pantcha-Tantra ou les cinq ruses.djvu/7 et 9. Qu'est-ce qu'il faut faire pour utiliser la police Parisienne? Ceciliawolf (d) 28 août 2023 à 17:33 (UTC)
- J'ai étudié le modèle Gothique. La documentation dit que "utilise l'extension WebFonts", mais l'extension "Webfonts" fut substituée par Universal Language Selector : la police UnifrakturMaguntia se trouve ici. Alors, c'est là que la police Parisienne devrait être? Ceciliawolf (d) 28 août 2023 à 20:25 (UTC)