Sur cette page et quelques autres de ce livre, le modèle {{c}} « centre » les deux lettres différemment. Comment régler ce problème ?--Raymonde Lanthier (d) 1 juillet 2020 à 13:50 (UTC)Répondre
- En fermant les balises OL avant le texte centré. Si c’était moi je n’utiliserais pas ces balises, je mettrais le numéro directement. Seudo (d) 1 juillet 2020 à 14:15 (UTC)Répondre
 Seudo : Merci ! Si j’ai utilisé les balises ol, c’est qu’elles permettent d’aligner correctement les numéros des proverbes — il y en a plus de 6000, comme l’indique le titre du livre.--Raymonde Lanthier (d) 1 juillet 2020 à 14:45 (UTC)Répondre
Seudo : Merci ! Si j’ai utilisé les balises ol, c’est qu’elles permettent d’aligner correctement les numéros des proverbes — il y en a plus de 6000, comme l’indique le titre du livre.--Raymonde Lanthier (d) 1 juillet 2020 à 14:45 (UTC)Répondre
En sous-page Bac à Sable, un changement à ce modèle est proposé pour permettre d’en définir la largeur (unité : em).
Exemples :
{{SéparateurDeTexte/Bac à sable}}
{{SéparateurDeTexte/Bac à sable | l=8}}
{{SéparateurDeTexte/Bac à sable | r | l=8}}
{{SéparateurDeTexte/Bac à sable | 2 | l=8}}
Est-ce que ceci répond à un besoin et y aurait-il autre chose à prévoir?
--Denis Gagne52 (d) 1 juillet 2020 à 18:03 (UTC)Répondre
- Cela me paraît tout à fait utile ! Oserais-je demander un paramètre de couleur ? je trouve tout à fait étrange la couleur actuelle de ce séparateur : pourquoi ne pas avoir choisi la couleur du texte, comme c’est le cas pour tous les autres :
{{-}}, {{—}}, {{...}}, etc. ? Utilisé avec un autre séparateur sur une même page, {{SéparateurDeTexte}} détonne complètement, en particulier dans sa version {{SéparateurDeTexte|2}}. — ElioPrrl (d) 1 juillet 2020 à 22:57 (UTC)Répondre
Voici avec un nouveau paramètre permettant de préciser la couleur (sinon la couleur actuelle est maintenue par défaut):
--Denis Gagne52 (d) 2 juillet 2020 à 01:03 (UTC)Répondre
- Modèle sympa. — Cantons-de-l'Est discuter 2 juillet 2020 à 18:21 (UTC)Répondre
- Super ! Un grand Merci
 ! — ElioPrrl (d) 2 juillet 2020 à 20:43 (UTC)Répondre
! — ElioPrrl (d) 2 juillet 2020 à 20:43 (UTC)Répondre
ElioPrrl : Tel que demandé, modification apportée et mise en production du modèle {{SDT}} avec couleur et largeur paramétrables :
{{SDT|l=6|c=t}}
- J’ai ajouté un choix de couleur « t » en espérant ainsi reproduire la couleur du texte de l’élément parent. --Denis Gagne52 (d) 12 juillet 2020 à 16:53 (UTC)Répondre
- Parfait ! Un grand merci
 — ElioPrrl (d) 12 juillet 2020 à 20:54 (UTC)Répondre
— ElioPrrl (d) 12 juillet 2020 à 20:54 (UTC)Répondre
Il y a beaucoup de conversations en cours à propos du futur des dénominations de marques et noms de notre mouvement. Nous espérons que vous avez pris part à ces discussions et que votre communauté est représentée.
Depuis le 16 juin, l'équipe de la Foundation chargée des dénominations de marque a lancé une enquête en 7 langues, à propos de 3 propositions de convention de dénomination. Certains membres de la communauté ont aussi exprimé leur opinion dans une Lettre ouverte de la communauté.
Notre but à travers cet appel est de recueillir les avis de tous les coins de la communauté, donc nous voudrions vous encourager à participer à cette enquête, à la Lettre ouverte, ou aux deux. L'enquête sera ouverte jusqu'au 7 juillet dans tous les fuseaux horaires. Nous analyserons et publierons les retours et avis rassemblées lors des ces discussions sur Meta-Wiki.
Merci de penser et participer au future de notre mouvement -- L'équipe de projet de Marque, 2 juillet 2020 à 13:43 (UTC)
Avis de non-responsabilité légale : veuillez noter que cette enquête est menée par un service tiers et que l'utilisation de vos informations et de vos réponses est régie par leur politique de confidentialité et leurs conditions de service. Pour plus d'informations sur la collecte et l'utilisation par la Fondation des informations recueillies dans le cadre de cette enquête, veuillez consulter notre déclaration de confidentialité.
- J'ai répondu au sondage. Nulle part il n'est mentionné le mot « Wikimedia », mais le mot « Wikipedia » est pareil à un slogan
 . — Cantons-de-l'Est discuter 2 juillet 2020 à 18:54 (UTC)Répondre
. — Cantons-de-l'Est discuter 2 juillet 2020 à 18:54 (UTC)Répondre
- J'ai répondu aussi, même si je n'ai pas compris toutes les questions. J'arrive un peu après la bataille en découvrant ce slogan : « D'ici à 2030, Wikimédia (ou Wikipédia) deviendra la principale infrastructure de l’écosystème de la connaissance libre, et quiconque partageant notre vision pourra se joindre à nous. » Je ne contribue pas à Wikipédia et Wikisource pour que Wikimachin soit la « principale » je-ne-sais-quoi. Je contribue parce que je trouve que la mise à disposition de la connaissance est utile pour les autres (et distrayante pour moi). Si demain un autre projet remplit ce besoin et fournit ce plaisir mieux que les projets soutenus par la fondation Wikimédia/Wikipédia, j’abandonnerai celle-ci sans nostalgie particulière pour ce qui n’est, après tout, qu’un énorme amas d’octets sur un réseau. Je ne dois pas être normal de ne ressentir aucun esprit d’entreprise (ni attachement à une « marque »). Seudo (d) 2 juillet 2020 à 20:27 (UTC)Répondre
- Ouaouh @Seudo, tu exprimes avec un parfaite exactitude le sentiment que j'ai eu à la troisième ou quatrième question de ce sondage, avant de faire un ctr w pour le renvoyer dans les limbes numériques dont je n'aurai pas dû le sortir. Peut-on pour une fois dans le domaine numérique échapper à la logique "Maître du monde" et entrepreneuriale ? Si WM/WP est dans une logique de marché, pourquoi ne pas rémunérer nos contributions (pour ma part un équivalent temps plein depuis juillet 2015) ? Pour penser différemment je recommande vivement une cure d'Alain Damasio, en particulier Les Furtifs, La Volte, 2019.--Cunegonde1 (d) 3 juillet 2020 à 04:45 (UTC)Répondre
- J'ai arrêté le questionnaire dès la page 2 : je ne vois pas en quoi mon identité sexuelle a à voir avec la question de "nom de marque" de la fondation.
- D'autre part, cette logique de marché me semble incompatible avec le mouvement libre auquel je contribue. Les dirigeants de la fondation me semblent la conduire vers une mauvaise pente.--Marceau (d) 3 juillet 2020 à 08:35 (UTC)Répondre
- Ce qui m'agace c'est que la WMF continue de nous demander notre opinion sur notre mouvement alors qu'elle n'en a rien à faire. Elle organise un processus démocratique parce que ça fait bien pour la forme, mais les résultats lui importent peu s'ils ne vont pas dans son sens. Je ne suis pas nécessairement contre un renommage, sur bien des points cela pourrait sûrement être bénéfique, mais en l'état tout le processus est une farce. --Jahl de Vautban (d) 3 juillet 2020 à 09:55 (UTC)Répondre
- Entièrement d'accord avec @Cantons-de-l'Est, @Seudo, @Cunegonde1 et @Jahl de Vautban ; j'ai commencé moi aussi à répondre au questionnaire, mais j'ai arrêté bien vite ; je n'en voyais pas trop l'intérêt (ce genre de déceptions m'arrive souvent avec les questionnaires WM). Je recommande aussi Damasio ;) --Acélan (d) 4 juillet 2020 à 19:11 (UTC)Répondre
- Quant à moi, j’ai répondu au questionnaire jusqu’au bout, mais j’avoue que je n’y ai pas compris grand chose, réponse un peu au hasard… A vrai dire je m’en fout du nom du wikimachin, ce qui m’intéresse c’est wikisource et le peu que j’ai contribué à wikipédia m’a vraiment dégoûté… --Le ciel est par dessus le toit Parloir 5 juillet 2020 à 08:44 (UTC)Répondre
- Bonjour à tous, personnellement je n'ai pas d'avis tranché sur ce que doit être le nom futur du mouvement WikiXX… par contre, je constate, à chaque fois que je parle de Wikisource dans une conversation avec des amis, que… quasiment personne ne connait !!! par contre le nom de Wikipédia est connu de presque tout le monde… Il y a donc encore un effort important à faire pour faire connaitre Wikisource auprès du grand public !!!!! --Lorlam (d) 19 juillet 2020 à 18:45 (UTC)Répondre
Bonjour,
je me suis permis d'ajouter les modèles {{Palette À corriger}} et {{Palette À valider}} sur les catégories Catégorie:Livres à corriger et Catégorie:Livres à valider. Il s’agit de modèles faisant des requêtes PetScan. Je les utilise pour rechercher les pages à la fois dans plusieurs catégories, comme pour détecter les dictionnaires à corriger ou les recueils à valider. J’ai pensé que c’était bien de le mettre là, vu que j’ai ressenti le besoin d’avoir cette info pour mieux contribuer. J’espère que ça sera utile à d’autres.
Bonne soirée, :) Lepticed7 (Viens tcharer ! :D) 2 juillet 2020 à 20:44 (UTC)Répondre
Bonjour à tout·es !
Je suis en train de transcrire l’Alphabet nouveau de Robert Poisson dans lequel il propose plusieurs nouvelles lettres pour le français dont une que je sais pas comment transcrire. Vous pouvez voir un exemple de ce caractère avec la première lettre du premier mot de cette page (« ?ose »). Il utilise ce caractère pour remplacer le digramme ch. Le soucis est que il n’est pas dans Unicode, du coup je l’ai transcris par ch, faute de mieux.
Est-ce que je continue de le transcrire ch ou je mets plutot un caractère Unicode dont la forme est proche (par exemple « ɕ » ou similaire) ?
Darmo (discussion) 3 juillet 2020 à 23:20 (UTC)Répondre
- Bonjour @Darmo. Il s'est tenu une discussion un peu similaire en avril dernier. Votre cas est un peu particulier dans la mesure où il s'agit véritablement d'une intention de l'auteur de proposer un nouvel alphabet et non pas d'une quelconque préférence typographique. Je ne crois pas qu'il y ait actuellement de manière optimale de retranscrire ce livre : substituer ch va à l'encontre de ce que voulait achever l'auteur, mais insérer un caractère typographique similaire mais finalement différent à la fois par sa forme et sa valeur ne me semble pas à conseiller. Je me demande à quel point il ne faudra pas passer par du CSS pour ce genre de cas, mais je suis incompétent pour vous proposer une solution. --Jahl de Vautban (d) 4 juillet 2020 à 07:29 (UTC)Répondre
- Merci de la réponse :) En attendant une solution, je vais continuer à transcrire « ch ». Je ferai passer un script plus tard pour changer si besoin. Darmo117 (Viendez parler !) 4 juillet 2020 à 10:05 (UTC)Répondre
- Bonjour Darmo117 :, une suggestion peut-être idiote, je ne sais pas, mais si tu maintiens le ch pourquoi ne pas le placer entre crochets [ch] pour bien marquer qu’il s’agit d’une substition, sinon une solution css serait de remplacer le caractère par une image du caractère comme ceci : "
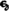 oze qi ne ſi treuve poin ?".--Cunegonde1 (d) 4 juillet 2020 à 16:28 (UTC)Répondre
oze qi ne ſi treuve poin ?".--Cunegonde1 (d) 4 juillet 2020 à 16:28 (UTC)Répondre
- Cunegonde1 : je me suis essayé à créer un caractère svg pour l'occasion => "
 oze". Si c'est possible de déployer ça de manière automatique via CSS, cela m'intéresse pour d'autres livres. --Jahl de Vautban (d) 4 juillet 2020 à 19:01 (UTC)Répondre
oze". Si c'est possible de déployer ça de manière automatique via CSS, cela m'intéresse pour d'autres livres. --Jahl de Vautban (d) 4 juillet 2020 à 19:01 (UTC)Répondre
- On pourrait en faire un modèle, genre modèle : "ch" ? ou autre mais avec un nom relativement court pour ne pas trop s’embêter. À défaut je peux effectivement mettre
[ch]. Darmo117 (Viendez parler !) 4 juillet 2020 à 20:41 (UTC)Répondre
- Darmo117 et Jahl de Vautban : Il y a déjà le modèle
{{caractère}}, alias {{X}}, exactement conçu pour ce genre de situations (remplacements de caractère par une image) ; les noms choisis d’ordinaire sont bien longs, mais ici ch me semble très bien. J’ai pris la liberté de modifier le modèle (j’annulerai bien sûr s’il le faut), et voici comment cela rend : {{X|ch}}oze- Parfait, merci ! Je vais utiliser ça du coup. Darmo117 (Viendez parler !) 4 juillet 2020 à 21:39 (UTC)Répondre
- Le modèle ajoute un grand espace vide à sa gauche quand il est dans un paragraphe, c’est particulièrement visible sur cette page. J’ai mal fait un truc ? J’ai inspecté le code HTML générée et il semble que la balise
span hérite de la règle CSS .pagetext p (qui ajoute un alinéa), ce qui me parait étrange. Darmo117 (Viendez parler !) 4 juillet 2020 à 22:45 (UTC)Répondre
- Darmo117 : Fait
 ! Cela venait du modèle
! Cela venait du modèle {{Rotation}}, qui utilise un bloc inline-block, configuration qui fait que le bloc reprend l’indentation de l’élément parent ; j’ai donc rajouté au code de ce modèle un text-indent:0. — ElioPrrl (d) 5 juillet 2020 à 10:30 (UTC)Répondre
- Nikel, merci ! Darmo117 (Viendez parler !) 5 juillet 2020 à 11:01 (UTC)Répondre
- Jahl de Vautban : , magnifique le svg. Pour ma part, j’ai du mal à tirer quelque chose de satisfaisant avec Inkscape.--Cunegonde1 (d) 5 juillet 2020 à 06:01 (UTC)Répondre
- Beau travail en effet ElioPrrl :et merci de me faire découvrir les possibilités du modèle caractère. Habituellement la taille d’une police de caractère se mesure sur la hauteur soit de sa hampe jusqu’au jambage. Considérant que pour la plupart des navigateurs 1em = 16px, je m’attendais à ce que la taille de l’image caractère soit plutôt définie comme suit : [[File:Poisson - Alphabet nouveau - Caractère ch.svg|x16px]] ce qui génère un caractère un peu plus haut soit:
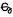 . Y a-t-il une raison pour avoir procédé autrement ? --Denis Gagne52 (d) 6 juillet 2020 à 13:26 (UTC)Répondre
. Y a-t-il une raison pour avoir procédé autrement ? --Denis Gagne52 (d) 6 juillet 2020 à 13:26 (UTC)Répondre
- Aucune ! J’ai simplement copié-collé l’image telle qu’utilisée par Jahl de Vautban dans son message ci-dessus
 . Il aurait fallu comparer à différentes tailles pour déterminer laquelle s’harmonise mieux avec le reste de l’alphabet ; mais cela dépend encore de la police, et si l’on se met à créer des versions avec empattements ou sans empattements, avec longueur de boucle conforme à Arial, Times, etc., autant demander la création du caractère à Unicode… Et puis, avec la police par défaut de Wikisource, la version de Jahl ne détonait pas, donc je l’ai gardée
. Il aurait fallu comparer à différentes tailles pour déterminer laquelle s’harmonise mieux avec le reste de l’alphabet ; mais cela dépend encore de la police, et si l’on se met à créer des versions avec empattements ou sans empattements, avec longueur de boucle conforme à Arial, Times, etc., autant demander la création du caractère à Unicode… Et puis, avec la police par défaut de Wikisource, la version de Jahl ne détonait pas, donc je l’ai gardée  — ElioPrrl (d) 6 juillet 2020 à 15:08 (UTC)Répondre
— ElioPrrl (d) 6 juillet 2020 à 15:08 (UTC)Répondre
- Ce caractère a fière allure peu importe qu’il ait une largeur de 10px ou une hauteur de x16px. En aucun cas je n’ai voulu l’offenser . --Denis Gagne52 (d) 6 juillet 2020 à 20:42 (UTC)Répondre
- Denis Gagne52 : j'ai tout de même pris bonne note de vos critiques et ait légèrement modifié le symbole, qui était jusqu'ici effectivement trop bas ! --Jahl de Vautban (d) 7 juillet 2020 à 20:57 (UTC)Répondre
- Jahl de Vautban : Ah ! Je vois maintenant ce qui a pu susciter la confusion. Quand je mentionnais qu’en utilisant x16px cela générait un caractère un peu plus haut, je faisais uniquement allusion à sa dimension qui dépasse quelque peu celle obtenue avec 10px. Il ne faut donc pas y voir une critique mais simplement un questionnement à savoir pourquoi, la taille de tous les caractères offerts par ce modèle, est définie par leur largeur plutôt que leur hauteur (normalement x16px). Je tenterai donc d’être plus précis la prochaine fois. --Denis Gagne52 (d) 8 juillet 2020 à 15:10 (UTC)Répondre
Darmo117, Jahl de Vautban et Cunegonde1 : la solution adoptée est correcte. Par contre, je suis curieux, la caractère API ɕ ne viendrait-il pas justement de Poisson ? Où trouver plus d'information sur ce caractère (je n’ai guère trouvé que cette critique mentionnant un « ch peu gracieux » ; je n'ai rien trouvé en partant du côté API pour connaître son origine…). Cdlt, VIGNERON (d) 21 juillet 2020 à 09:23 (UTC)Répondre
- Salut, ça me parait improbable, même si j’ai trouvé aucune source sur l’origine du caractère ɕ. Il semble qu’il a d’abord été utilisé pour la transcription du yi en Chine (cf. WP) puis après intégré dans l’API. Darmo117 (Viendez parler !) 21 juillet 2020 à 09:33 (UTC)Répondre
Bonjour,
D'après l'avis envoyé sur meta wiki, la création d'un nouveau modèle va nous obliger à renommer le raccourci {{=}} utilisé pour le modèle {{SéparateurDeTexte}}. @Alexis Jazz, qui a déposé l'avis, propose d'effectuer l'opération à l'aide d'un robot. Reste à se mettre d'accord sur un nouveau raccourci. Des idées ? --Acélan (d) 5 juillet 2020 à 07:03 (UTC)Répondre
- Bonjour Acélan, merci de l'info. Je propose très simplement
{{SDT}}. --Jahl de Vautban (d) 5 juillet 2020 à 07:44 (UTC)Répondre
- Merci ; c'est simple et c'est une bonne idée. --Acélan (d) 5 juillet 2020 à 08:51 (UTC)Répondre
- Ou encore le doubler {{==}} ce qui ne devrait pas trop traumatiser ceux qui s’étaient habitués à {{=}} --Denis Gagne52 (d) 5 juillet 2020 à 12:45 (UTC)Répondre
- Je pense que
{{SDT}} est préférable : on ne risque pas trop de voir le même problème se reproduire. --Acélan (d) 5 juillet 2020 à 13:35 (UTC)Répondre
 pour SDT--Denis Gagne52 (d) 6 juillet 2020 à 21:05 (UTC)Répondre
pour SDT--Denis Gagne52 (d) 6 juillet 2020 à 21:05 (UTC)Répondre
- @Denis Gagne52 BTW, there is nothing stopping you from having both.
{{=}} is also a redirect, so you could just create redirects at both {{SDT}} and {{==}}. The only question (for now) is what to replace existing instances of {{=}} with. I've tested the mass editing at [1] and it works. (I've already done this replacement for nvwiki using the same method) Alexis Jazz (d) 6 juillet 2020 à 22:21 (UTC)Répondre
- pour SDT. Quant à créer ensuite un raccourci
{{==}}, ce n’est pas forcément une bonne idée car la logique de {{SéparateurDeTexte}} n’est pas la même que celle des modèles {{-}}, {{--}}, {{---}} et {{----}}. Le premier a une largeur par défaut égale à celle de la page, alors que les autres ont une largeur proportionnelle au nom même du modèle. Si on les créait, {{==}}, {{===}}, etc., devraient avoir une longueur comparable à {{--}}, {{---}}, etc. Seudo (d) 7 juillet 2020 à 08:29 (UTC)Répondre
- That's indeed a good reason to skip
{{==}} entirely. I won't vote as I'm no regular here, I just offer replacing existing usage of {{=}}. Alexis Jazz (d) 7 juillet 2020 à 16:11 (UTC)Répondre
- I could replace existing usage once you agree on the new name and an edit summary I should use.
I will require at least the noratelimit right which is included in the "Créateurs de comptes" user group. You would probably also want to make me autopatrolled. (Auto-patrouillés) Only Utilisateur:Zyephyrus can add me to "Créateurs de comptes". Alexis Jazz (d) 5 juillet 2020 à 14:47 (UTC)Répondre
- Looks like I could also do it without
noratelimit if needed, though it would be more convenient with it. Alexis Jazz (d) 6 juillet 2020 à 00:57 (UTC)Répondre
{{SDT}} me va. — Cantons-de-l'Est discuter 6 juillet 2020 à 12:10 (UTC)Répondre
{{SéparateurDeTexte}} is used on almost 3000 pages, {{=}} is used on almost 12000 pages. {{Séparateur de texte}} is used on only 9 pages. Alexis Jazz (d) 6 juillet 2020 à 15:04 (UTC)Répondre
- Fait J'ai créé
{{SDT}}. Seudo (d) 7 juillet 2020 à 20:21 (UTC)Répondre
- @Seudo I'll wait for an admin (perhaps @Acélan) to ask me to do the replacement and provide an edit summary for me to use. Alexis Jazz (d) 7 juillet 2020 à 22:33 (UTC)Répondre
- Alexis Jazz : I think it is OK for everybody.
- For the summary : I propose "Remplacement du raccourci pour le modèle Séparateur de texte" if it is not to long. --Acélan (d) 8 juillet 2020 à 06:47 (UTC)Répondre
- Acélan : I'll start the first batch. Alexis Jazz (d) 8 juillet 2020 à 06:59 (UTC)Répondre
- I thought that the bot would use
{{SéparateurDeTexte}}, not {{SDT}} (in order to avoid a redirection). cf. [2] Seudo (d) 8 juillet 2020 à 07:49 (UTC)Répondre
- Acélan : Oops, I'm not autoconfirmed yet, so thousands of edits were rejected. (my account is only 3 days old instead of the required 4) Unless Utilisateur:Zyephyrus makes me an account creator (Créateurs de comptes), this will have to wait until tomorrow. Seudo : if I were replacing
{{=}} with {{SéparateurDeTexte}} there wouldn't have been any need to discuss {{==}} versus {{SDT}}. After the replacement is done you might want to move {{SéparateurDeTexte}} to {{SDT}}, but that's up to you. Alexis Jazz (d) 8 juillet 2020 à 13:31 (UTC)Répondre
- Alexis Jazz : : Even if you were replacing
{{=}} with {{SéparateurDeTexte}}, there would have been a need to discuss, because we French are too lazy to type such a long name as séparateur de texte : as you can see, the most used version of this model is {{=}} ! So we definitely need a short name. I think Seudo said that it would have been better to replace automatically by {{SéparateurDeTexte}} not for the ease of "human" contributors, but because it would shorten the loading and/or export time of the pages. — ElioPrrl (d) 8 juillet 2020 à 15:55 (UTC)Répondre
- Oui, c’est cela. J’ignore si la charge est significative ou pas (mais c’est toujours mieux d’éviter de multiplier les modèles lorsqu'on peut l'éviter facilement). Seudo (d) 8 juillet 2020 à 16:37 (UTC)Répondre
- @ElioPrrl @Seudo I don't think load times are affected significantly, but if that's the concern, replacing with
{{SéparateurDeTexte}} would still not be a good idea because any new pages that are created are more likely to use {{SDT}} because the French are lazy.[1] So you'd be better off moving {{SéparateurDeTexte}} to {{SDT}} to avoid redirects being used. Alexis Jazz (d) 8 juillet 2020 à 17:22 (UTC)Répondre
- Ok ! Seudo (d) 8 juillet 2020 à 20:22 (UTC)Répondre
- Resumed replacing. Alexis Jazz (d) 9 juillet 2020 à 01:09 (UTC)Répondre
- Merci Alexis Jazz ! ; j'ai remplacé les quelques occurrences qui traînaient (dans les documentations de modèles de séparateurs, essentiellement), et j'ai supprimé le raccourci, pour éviter que les wikisourciens qui ne sont pas là actuellement n'utilisent le modèle, faut d'être informés. --Acélan (d) 9 juillet 2020 à 07:54 (UTC)Répondre
- @Acélan: Excellent! I probably missed Page:Brillat-Savarin - Essai historique et critique sur le duel, 1819.djvu/11 and Page:Bulletin du comité historique des arts et monuments, volume 1, 1849.djvu/23 because the template was in includeonly tags, which must have prevented it from showing up in the search results. I was confused why Bulletin du comité historique des arts et monuments/Tome 1/1 and Essai historique et critique sur le duel wouldn't go away from Spécial:Pages liées/Modèle:=. Alexis Jazz (d) 9 juillet 2020 à 13:03 (UTC)Répondre
Après les demandes de @Raymonde Lanthier et @Fabrice Dury en mai et en juin, j’ai finalement cédé aujourd’hui même aux raisons de @Jahl de Vautban quant au problème des paragraphes sans alinéa : j’ai créé le modèle {{SansAlinéa}}, alias {{SA}}, et des déclinaisons en ouverture et en fermeture pour le mode Page.
Comme je le précise dans la documentation, ce n’est pas un énième avatar de {{Br0}}, en ce que d’abord il nécessite d’envelopper le paragraphe non indenté (y compris lorsque celui-ci court sur deux pages, d’où les variantes /o et /f), et en ce qu’ensuite il introduit, sauf précision contraire en paramètre, la même marge verticale avant et après le paragraphe sans alinéa que pour un paragraphe normal. Je n’ai pas pensé devoir enlever ces marges sans déséquilibrer la composition, puisque souvent la situation se présente ainsi :
D’abord un début de paragraphe tout ce qu’il y a de plus banal, présentant alinéa en chef et marge verticale supplémentaire avant et après lui,
puis une interruption centrée,
et la reprise du paragraphe, cette fois-ci sans alinéa, mais tout autant espacée de l’interruption que le début de paragraphe : elle est donc précédée d’une marge verticale égale à celle suivant le début de paragraphe ; enfin, elle doit de toute manière être suivie par cette même marge, puisqu’elle signale la fin du paragraphe.
Je suis pour l’instant en train de mettre à l’essai {{SA}} et ses modèles fils sur le Gorgias de Platon, et de corriger au fur et à mesure les problèmes qui se présentent. Si quelques-uns de vous ici voulaient bien essayer ces modèles, et me communiquer leurs remarques (dysfonctionnements, paramètres à ajouter, que sais-je encore), je leur en serais extrêmement reconnaissant. Si de plus vous avez quelque compétence en HTML, je ne saurais trop vous encourager à jeter un coup d'œil à mon code ; je ne pense pas qu’il soit optimal. Tous vos commentaires peuvent être ajoutés à ma page de discussion, dans le sujet Requête de modèle ouvert par Jahl. En espérant être utile — ElioPrrl (d) 8 juillet 2020 à 14:10 (UTC)Répondre
- Merci ElioPrrl ! ; je ne pense pas avoir trop le temps de tester avant mon départ en vacances, et mes compétences techniques sont de toute façon limitées, mais j'apprécie moi aussi la création de ce modèle. --Acélan (d) 9 juillet 2020 à 07:56 (UTC)Répondre
- Merci ElioPrrl ! pour cette création. Le modèle SA marche bien dans les premiers cas simples que j'ai testés. Je ferai des remarques, si je rencontre des difficultés… Cordialement Fabrice Dury (d) 11 juillet 2020 à 12:35 (UTC)Répondre
Quelqu’un saurait-il s’il existe une version de Sabine ailleurs qu’à la BnF car la page 204 nécessite un remplacement. Merci. Hektor (d) 9 juillet 2020 à 16:52 (UTC)Répondre
- J’en ai trouvé un ici. Contact Hektor (d) 9 juillet 2020 à 20:15 (UTC)Répondre
- A priori le bouquin est aussi dans les bibliothèques de la ville de Paris(voir ici). --Shev123 (d) 10 juillet 2020 à 07:40 (UTC)Répondre
- Dans ce cas il y a deux possibilités, si quelqu’un peut y aller, c’est soit vérifier et donner le mot manquant, soit modifier le DjVu en insérant une nouvelle page 204. Merci. Hektor (d) 10 juillet 2020 à 11:20 (UTC)Répondre
- Il y a aussi une solution de secours à la BnF. Celle-ci m’a répondu : « La BnF dispose d’un autre exemplaire qui n’est pas numérisable. Néanmoins la microfiche est consultable en Bibliothèque de Recheche : MFICHE 8-Y2-13517 » Hektor (d) 10 juillet 2020 à 12:45 (UTC)Répondre
- Hektor :Fait J’ai remplacé la page 204 (210 du djvu) défectueuse par la page en lien donnée sur la pdd--Cunegonde1 (d) 17 juillet 2020 à 17:15 (UTC)Répondre
- Cunegonde1 : Mille mercis ! Hektor (d) 17 juillet 2020 à 19:52 (UTC)Répondre
Bonjour à tous,
J’ai l’honneur de vous présenter Wikipédia abstraite (Abstract Wikipedia en anglais), un nouveau projet approuvé unanimement par le conseil d’administration de Wikimedia Foundation. Il propose une nouvelle manière de générer du contenu encyclopédique à enrichir de manière indépendante de la langue, ce qui permettra à davantage de contributeurs et de lecteurs de partager davantage de connaissances dans plus de langues. C’est une approche qui vise à créer une coopération entre les communautés quelle que soit leur langue de manière plus facile sur nos projets, et d’améliorer la durabilité de notre mouvement en augmentant les possibilités pour participer, en améliorant l’expérience des lecteurs de toutes les langues, et d’innover dans la connaissance libre en connectant les forces de notre mouvement pour créer quelque chose de nouveau.
Il s’agit de notre premier nouveau projet depuis plus de sept ans. Abstract Wikipedia (Wikipédia abstraite) a été proposé comme nouveau projet par Denny Vrandečić en mai 2020[1] après des années de préparation et recherche, ce qui a conduit à un plan détaillé mais aussi à des discussions animées dans les communautés de Wikimedia. Nous savons que l’énergie et la créativité de la communauté se sont souvent confrontées à la barrière de la langue ; une information disponible dans une langue peut ne pas l’être dans une autre. La Wikipédia abstraite se veut semblable à une Wikipédia, mais construite sur la base des modèles conceptuels de Wikidata qui sont puissants et indépendants de la langue. Elle aura pour objectif de permettre aux contributeurs de créer et maintenir des articles Wikipédia transversaux à notre monde Wikimédien polyglotte.
Le projet permettra aux bénévoles d’assembler les fondamentaux d’un article en utilisant les termes et les entités de Wikidata. Wikidata utilisant des modèles conceptuels qui sont identiques dans toutes les langues, il devrait être possible de les utiliser et d’étendre ces briques de base de connaissances pour créer des modèles d’articles qui ont également une portée universelle. En utilisant du code, les contributeurs pourront traduire ces « articles » abstraits dans leurs propres langues. Si cette aventure est un succès, cela pourrait permettre à tout le monde de lire des articles sur n’importe quel sujet de Wikidata dans sa propre langue.
Comme vous pouvez l’imaginer, ce travail va nécessiter beaucoup de développement logiciel, et beaucoup de coopération entre les Wikimédiens. Pour rendre cet effort possible, Denny rejoindra la fondation comme salarié en juillet et dirigera cette initiative. Vous connaissez peut-être Denny en tant que créateur de Wikidata, ou en tant que membre de la communauté depuis longtemps, comme ancien salarié de Wikimedia Allemagne, ou encore comme ex-administrateur de la Wikimedia Foundation[2]. Nous sommes enthousiasmé à l’idée que Denny apporte ses compétences et son expertise sur ce projet et les logiciels et technologies de la fondation, et qu’il travaille avec les équipes d’intermédiaires avec la communauté.
Il est important de se rappeler que c’est un projet expérimental, et que chaque projet et communauté Wikipédia a ses propres besoins. Ce projet pourrait fournir de nombreux avantages à certaines de ces communautés. D’autres s’engageront peut-être moins. La communauté de chaque Wikipédia sera libre de choisir et modérer la manière dont elle souhaite utiliser ou non le contenu de ce projet.
Nous nous réjouissons à l’idée que ce nouveau wikiprojet puisse faire progresser l’équité des connaissances en améliorant la possibilité d’y accéder. Cela nous invite aussi à prendre en compte et à nous engager sur des points critiques concernant la manière les connaissances sont construites et leurs destinataires. Nous attendons impatiemment de travailler en coopération avec les communautés pour réfléchir à ces questions importantes.
Il y a beaucoup à faire puisque nous commençons seulement à concevoir un plan pour la Wikipédia abstraite en collaboration étroite avec nos communautés. Je vous encourage à vous impliquer en vous rendant sur la page du projet et en rejoignant la nouvelle liste de diffusion [3]. Nous reconnaissons que la Wikipédia abstraite est ambitieuse, mais nous reconnaissons aussi son potentiel. Nous vous invitions tous à nous rejoindre sur un nouveau chemin, inexploré.
Bien à vous,
Katherine Maher (Directrice générale, Wikimedia Foundation)
- ↑ Abstract Wikipedia
- ↑ Utilisateur:Denny
- ↑ Liste de diffusion de la Wikipédia abstraite
Sent by m:User:Elitre (WMF) 9 juillet 2020 à 20:10 (UTC) - m:Special:MyLanguage/Abstract Wikipedia/July 2020 announcement Répondre
Bonjour,
Il reste 3 pages à corriger sur Facino Cane ; apparemment il y a des erreurs grammaticales non corrigées par Balzac apparemment ; êtes-vous d'accord pour utiliser le modèle corr à ce propos ? Merci. Hector (d) 10 juillet 2020 à 09:48 (UTC)Répondre
- Bonjour @Hector. Sans problème pour les deux premières, je suis plus réservé pour la virgule/point virgule, son emploi ayant assez varié. Ces coquilles ne sont pas forcément du fait de Balzac lui-même : elle peuvent résulter d'une inattention du typographe et être répétées sur plusieurs éditions jusqu'à ce qu'enfin on les remarque. Je ne dispose pas d'une édition moderne de Facino Cane, mais ça pourrait valoir le coup de regarder la solution qui y est adoptée. --Jahl de Vautban (d) 10 juillet 2020 à 10:35 (UTC)Répondre
- Hector : Dans ces cas-là, je consulte soit l’édition de référence (la dernière parue du vivant de l’auteur, le plus souvent ; pour savoir quelle édition privilégier, il suffit souvent de consulter une bonne bibliographie de l’auteur), soit l’édition de la Pléiade. Ici, éditeur Houssiaux, donc, si je ne me trompe pas, on a déjà affaire à l’édition de référence, celle dite de Furne. Je me tourne alors vers la Pléiade : l’éditeur scientifique corrige les trois fois (y compris le point virgule et le mot barcarolle), sans même indiquer de variantes ; on peut lui faire confiance, la Comédie humaine par Castex est l’un des meilleurs ouvrages de la collection.
- Pour ceux qui ne le sauraient pas, et qui comme moi n’auraient pas un seul volume de la Pléiade dans sa bibliothèque, sachez qu’il est possible, sur le site de la collection, de faire une recherche « dans les livres », et d’avoir un aperçu du passage concerné (un exemple). — ElioPrrl (d) 10 juillet 2020 à 12:37 (UTC)Répondre
- Excellent, merci à vous deux ; je ne connaissais pas le site, c'est bien utile en effet, j'ai quelques pléiades dans ma bibliothèque, mais je suis encore très loin de l'intégrale ! Hector (d) 10 juillet 2020 à 14:33 (UTC)Répondre
- Hector : notez que dans le lien indiqué par @ElioPrrl, le point virgule est placé après tous les autres et non pas après dédaigneuse. --Jahl de Vautban (d) 10 juillet 2020 à 19:12 (UTC)Répondre
- Effectivement, merci! Hector (d) 10 juillet 2020 à 21:13 (UTC)Répondre
Bonjour, j’essaie désespérément de réaliser une liste avec des points de suite telle qu'ici. J’ai essayé avec les listes automatiques ou non et le modèle {{filet}}, mais ce n’est pas satisfaisant dans ce cas avec des alignements de plusieurs colonnes, avec le modèle {{table}} c’est un peu mieux, mais ce n’est toujours pas présentable : les vagues dans les colonnes donnent le mal de mer. J’ai cherché du css (le tag leaders), mais ça a l’air super compliqué comme on le voit ici. L’une ou l’un d’entre vous a-t-il trouvé une solution à ce problème récurrent ? Si oui, ce serait super sympathique de la partager. Bonne soirée.--Cunegonde1 (d) 11 juillet 2020 à 14:28 (UTC)Répondre
- Cunegonde1 (d · c), J'ai essayé ce que je connais de CSS et de
{{table}}, mais je ne parviens pas à créer un alignement vertical qui éliminerait les vagues. En passant, on ne peut pas utiliser la proposition de w3.org (qui semble valide) parce qu'il faut créer une page CSS distincte et ça exige de modifier l'interface de Wikisource, ce qui est Mal. — Cantons-de-l'Est discuter 11 juillet 2020 à 15:04 (UTC)Répondre
- Cunegonde1 : Dans ce cas, j’utilise le modèle
{{table}} dans un tableau : une première colonne contenant les étiquettes dans le modèle {{table}}, sans précision de numéro de page ; puis, d’autres colonnes avec les données numériques, alignées en bas et ferrées à droite, quitte à jongler avec colspan : cf. ici. Mais plus ça vient, moins je prends la peine de mettre ces points de conduite ; {{table}} ne dispose pas de vrais points de conduite, mais utilise en fait un bidouillage (une bordure en pointillés surélevée), qui rend pas toujours bien à l’export (en particulier, la boîte contenant le titre n’est pas transparente, mais a un fond blanc imposé, ce qui se remarque tout de suite quand la couleur d’arrière-plan de la liseuse est différente, ou quand vous survolez les numéros de page en marge des transclusions). Je ne crois pas que {{table}} utilise la fonction leader() présentée dans le lien ; peut-être, si cette propriété est meilleure, pourrait-ce être un projet d’implémenter de vrais points de conduite. En attendant, je n’ai pas d’autre solution. — ElioPrrl (d) 11 juillet 2020 à 15:18 (UTC)Répondre
- Merci de vos tentatives, j’ai bricolé une liste traditionnelle avec le modèle
{{filet}} qui est dans la pdd de la page, ça fait un peu moins de vagues, je vais continuer d’y travailler.--Cunegonde1 (d) 11 juillet 2020 à 15:21 (UTC)Répondre
- Cunegonde1 : Le mieux, je pense, c'est de faire un tableau : voir ma proposition. Manseng (d) 11 juillet 2020 à 16:09 (UTC)Répondre
- Manseng :C’est super, grand Merci je garde le modèle car ce n’est pas la première fois que je me trouve devant cette situation, et c’est un excellent moyen de procéder, je n’avais jamais utilisé le modèle
{{table}} de cette manière. Comme quoi 5 ans de fréquentation assidue de wikisource ne suffisent pas à en maîtriser toutes les arcanes.--Cunegonde1 (d) 11 juillet 2020 à 16:47 (UTC)Répondre
- Ce serait bien quand même que quelqu’un, un jour, nous crée un modèle qui permet de faire des points de suite dans un tableau sans avoir à ruser. -Hektor (d) 11 juillet 2020 à 20:15 (UTC)Répondre
- J'aimerais faire remarquer que le modèle
{{table}} est conçu pour les tables des matières avec numéro de pages.
- Si on l'utilise dans une tableau, les pointillés sont enlevés ainsi que le numéro de page, car la notion de page (modèle
{{pli}}) n'est plus pertinente dans une version électronique pour une table des matières (ePub, Mobi ainsi que pdf).
- J'ai aussi vu le modèle pli être utilisé dans un tableau pour indiquer une donnée. Le pointillé et la donnée (c'est bien plus grave !) ne sont PAS transférés aux versions électroniques.
- Je reprends la suggestion de Utilisateur:Hektor qu'il nous faudrait « un modèle qui permet de faire des points de suite dans un tableau » et qui soit transférable en version électronique.
- (ceci dit, j'utilise souvent le modèle table pour avoir des pointillés dans un tableau, mais en toute connaissance de cause...) --Viticulum (d) 12 juillet 2020 à 17:52 (UTC)Répondre
Viticulum : Je ne suis pas tellement familier avec les tableaux que j’ai tendance à éviter mais p-e pas dans cette situation. Si on convient que les points de suite se retrouveront toujours dans la première colonne, on pourrait possiblement obtenir ce résultat en regroupant tous les attributs dans un seul style css :
| Proposeur :
|
Hektor
|
| Secondeur :
|
Viticulum
|
donc sans avoir à construire de modèle. --Denis Gagne52 (d) 13 juillet 2020 à 22:13 (UTC)Répondre
À bien y penser, il sera plus facile de faire évoluer un modèle.
Voici donc ma proposition :
-
- Modèle utilisé à l’intérieur d’un Tableau
Test concluant en format epub. Quelqu’un a un nom à proposer pour ce modèle ??--Denis Gagne52 (d) 14 juillet 2020 à 03:28 (UTC)Répondre
- Je propose : {{Modèle:Pointsdesuite}} Hektor (d) 14 juillet 2020 à 13:48 (UTC)Répondre
- Merci beaucoup Denis Gagne52 : de te pencher sur cette situation. J'ai joué avec la largeur du tableau ainsi que la largeur des colonnes (2 notions différentes). On voit que les pointillés ne vont pas jusqu'à la fin de la cellule, ce qui est essentiel. De plus il est possible qu'il y ait des pointillés dans des colonnes du milieu aussi (voir exemple et exemple). Le nom {{Modèle:Pointsdesuite}} me convient mais idéalement avec un raccourci genre : Pds. Merci --Viticulum (d) 14 juillet 2020 à 19:32 (UTC)Répondre
Viticulum : Donc {{Modèle:Pointsdesuite}} ce sera. Et pour le problème soulevé, c’est que, dans l’exemple, la largeur du Pds avait été fixée à 15em. Pour couvrir toute la cellule, il faudra lui attribuer une largeur de 100% comme montré sur la ligne Viticulum. Je vérifie la possibilité d’attribuer par défaut une largeur de 100% et te revient là-dessus. Merci de tester le comportement à l’intérieur d’un tableau. --Denis Gagne52 (d) 14 juillet 2020 à 20:05 (UTC)Répondre
- Merci Denis Gagne52 :. En effet je préfère une largeur par défaut de 100%, quitte à utiliser un paramètre dans les cas où il est utile de diminuer. --Viticulum (d) 14 juillet 2020 à 20:20 (UTC)Répondre
- Denis Gagne52 : Serait-il possible d'avoir un pointillé plus petit comme on a actuellement : sur cette page voir la ligne Turbit versus les pointillés actuel. Merci --Viticulum (d) 15 juillet 2020 à 01:18 (UTC)Répondre
Viticulum : voir les motifs possibles en ajoutant deux nouveaux paramètres Modèle:Pointsdesuite/Banc d’essai --Denis Gagne52 (d) 15 juillet 2020 à 03:22 (UTC)Répondre
- Je ne pensais pas un jour revenir sur ce genre d'horreur, mais ça fonctionne -Jahl de Vautban (d) 15 juillet 2020 à 07:25 (UTC)Répondre
- Denis Gagne52 : Wow ! super. Pour ma part je vais privilégier le pointillé le plus discret, car s'il y en a beaucoup dans un tableau, cela devient trop « intense ». Merci de tout tes efforts. --Viticulum (d) 15 juillet 2020 à 18:45 (UTC)Répondre
Cette bibliothèque a un exemplaire de Livre:Marc de Montifaud Sabine 1882.djvu, de la même édition que celle de Gallica. Je ne sais pas si certains contributeurs français habitent près mais il serait intéressant de finaliser ce livre en obtenant une photographie du texte de la page 204 qui malheureusement est effacé sur la version de Gallica. J'ai tenté de retrouver un autre facsimilé mais sans succès. Attention, cette bibliothèque est ouverte sur RV seulement pour des consultations spéciales… Je crois que nous pouvons le justifier… --Ernest-Mtl (d) 12 juillet 2020 à 15:35 (UTC)Répondre
- Voir plus haut. Hektor (d) 12 juillet 2020 à 16:55 (UTC)Répondre
- Grâce à votre lien, j'ai trouvé le numéro de téléphone et l'adresse électronique de la bibliothèque Marguerite-Durand. Je téléphonerai dès demain. Peut-être pourrons-nous alors finaliser la transclusion de « Sabine ». Je vous tiens au courant bien entendu. Merci à Hektor et à Ernest-Mtl pour leurs recherches.Tipram (d) 12 juillet 2020 à 19:12 (UTC)Répondre
- Ernest-Mtl et Tipram : Si quelqu’un sait comment insérer une page voici un lien vers la page 204 de Sabine numérisée fournie par la bibliothèque de l’Université Vanderbilt. Hektor (d) 14 juillet 2020 à 20:26 (UTC)Répondre
- La Bibliothèque que Ernest a pris la peine d'indiquer vient de m'envoyer en PDF la page à problème. malheureusement, j'ignore comment l'insérer. En tout cas, je confirme que le mot illisible est bien « l'outrage », conformément à la correction effectuée par Hektor. Bonne journée à tous. Tipram (d) 15 juillet 2020 à 11:36 (UTC)Répondre
Venant de finir Éthique, Droit et Politique d'Arthur Schopenhauer, je me pose une question oiseuse: Wikisource est-il utile pour les grands textes (comme l'oeuvre de Schopenhauer) ou les petits textes (comme Sabine de Marc de Montifaud). On trouve Schopenhauer en ligne sans problème, y compris en livre numérique gratuit de bonne qualité ( https://www.schopenhauer.fr/oeuvres.html ) donc à quoi bon investir pour en faire un exemplaire de plus, alors que Sabine (dont l'auteur est une femme) est introuvable ailleurs et mérite pour cela l'effort des contributeurs (j'ai donné, je trouve que c'est moins digne d'être lu que Schopenhauer, mais ça ne retire rien à mon discours). Même idée pour les romans québécois (j'ai donné aussi). Que faut-il penser ? --Wuyouyuan (d) 13 juillet 2020 à 09:02 (UTC)Répondre
- Sabine est aussi facile à trouver ailleurs (sur Gallica), mais la centralisation sur un site pérenne, bien organisé, dans un format informatique commun (donc utilisable par des outils d’analyse), de textes littéraires, philosophiques, scientifiques, culinaires… présente un intérêt en soi, quel que soit le texte. Donc chacun peut y mettre les ouvrages qui l’intéressent sans avoir à faire un bilan de l’utilité sociale de son action. Fais ce que voudras est, je crois, ou pourrait être la devise principale de l’abbaye de Wikisource. Seudo (d) 13 juillet 2020 à 09:32 (UTC)Répondre
- Les quelques ouvrages auxquels j’ai contribué sont également tous disponibles, sous un format ou un autre, sur d’autres sites. À ma connaissance, aucun n’est communautaire ; signaler une seule coquille, quand c'est seulement possible, nécessite au mieux de remplir un formulaire et d’espérer que quelqu’un le lise. Wikisource a l’immense avantage que n’importe qui peut, en quelques clics, améliorer un texte (ou le détériorer, mais c’est bien plus rare). De plus, la retranscription de la plupart des textes s’appuie sur un fac-similé, ce qui est loin d'être fréquent ailleurs — ou alors ce sont des images et pas un texte. Mais même à laisser tomber ces considérations, contribuer à un texte qui m'intéresse me permet de le connaître bien plus en profondeur qu'une simple lecture sur un autre site, et tant mieux si au passage cela permet à d'autres de le lire. --Jahl de Vautban (d) 13 juillet 2020 à 10:12 (UTC)Répondre
- Je suis tout à fait d’accord avec ce que dit Jahl de Vautban : Wikisource est plus souple, et surtout beaucoup mieux sourcé que d’autres sites de ce genre. Je travaille par exemple depuis mon arrivée à la relecture des dialogues de Platon : toutes les éditions en ligne, ou presque, reprennent les traductions de Chambry ou de Cousin (je n’ai rien contre le travail du premier, mais quant au second, on a assez montré la faiblesse philologique de ces travaux et sa tendance à imprimer sa propre philosophie aux auteurs qu’il traduisait), et ce, plus d’une fois, sans même mentionner le traducteur : ça laisse plus qu’à désirer pour quelqu’un qui voudrait découvrir de manière un peu circonstanciée la philosophie de Platon. Wikisource, lui, mentionne les traducteurs, ne coupe pas leurs notices ou leurs notes, permet de consulter plusieurs traductions pour un même passage, etc. ; cela ne remplace pas une bonne édition de référence commentée, mais c’est mieux que rien, et surtout mieux que tous ces PDF distribués pour ainsi dire à la sauvette sur Internet.
- D’ailleurs, je porte beaucoup d’intérêt à la question du choix de l’édition ; si aujourd’hui, pour reprendre le même exemple, je relis le Platon de la CUF, et non celui de Chambry ou de Saisset, c’est parce que c’est l’édition de référence pour l’agrégation de lettres classiques ; pour Buffon (sans aucun doute un grand texte, soit dit en passant, tant par ses dimensions que par son influence scientifique et littéraire sur les idées et les travaux des xviiie et xixe siècle [« la plus grande plume du siècle », disait Rousseau ; et allez comprendre Chateaubriand, Lamarck ou Darwin sans Buffon] ; et pourtant aucune parution électronique gratuite !), j’ai consulté les bibliographies des extraits Pléiade et des extraits des PUF pour importer une édition fiable, sans coupures, sans corruption du texte, imprimée d’après la première édition, non d’après des éditions de seconde main, enfin une édition qui serve encore aujourd’hui de référence pour l’établissement du texte. Combien d’ePub offrent de telles garanties ? Je suis persuadé que Wikisource ne peut que s’enrichir en publiant les grands textes, dans des éditions différentes, de plus en plus récentes (et oui, ça compte souvent pour la qualité de l’information de l’édition !), et que, si l’on veut que notre site ne reste pas une entreprise morte, que personne ne viendrait consulter, il faut commencer par là, en publiant tous les grands textes, dans la meilleure édition du domaine public qui soit.
- Enfin, la correction des grands textes n’exclut pas l’enrichissement par des textes de moindre importance patrimoniale : certains corrigent les œuvres de femmes, d’autres de minorités ; j’avoue que, par tempérament personnel, ces critères de sélection me semblent à proscrire (ils reflètent bien plus nos démons actuels que les préoccupations de l’époque ; et puis, d’une biographie d’auteur, ou d’un trait de son identité, on ne saurait jamais en tirer un seul gage de la qualité littéraire, scientifique ou culturelle de son œuvre), mais j’ai moi-même mes propres marottes (les textes mathématiques et scientifiques par exemple), et jamais je ne dissuaderai quelqu’un ici de corriger un livre, sous prétexte ou bien que c’est une nullité sur le plan littéraire ou scientifique, ou bien que c’est un grand texte qui n’a pas besoin de nous pour être lu.
- Décidément, on ne se corrige pas : j’aurais encore été bien long… Vous le dites vous-même, votre question est oiseuse ; peut-être pas tant que ça, vu qu’elle suscite les réactions, et bien vite encore ! — ElioPrrl (d) 13 juillet 2020 à 13:40 (UTC)Répondre
- "Petits" et "grands" textes sont, sans aucune hiérarchie, le reflet de la pensée et de l’imaginaire de leur époque. Les "petits" textes en disent souvent davantage sur la façon dont les gens vivaient (réellement ou fantasmatiquement) leur existence. Par ailleurs, la lecture assidue et besogneuse de ces textes souvent oubliés est un excellent préservatif contre une manie bien actuelle : celle de juger nos prédécesseurs avec les idées à la mode du jour. Enfin la transcription de la Relation historique de la peste de Marseille en 1720 – "petit" ou "grand" texte ? – pendant le confinement a été fort aidante pour relativiser les comparaisons hâtives entre des situations fort différentes à bien des égards.--Cunegonde1 (d) 13 juillet 2020 à 12:33 (UTC)Répondre
- Il y a aussi les textes disponibles uniquement sur wikisource, car absents même à la Bnf, comme par exemple des livres d'un certain baron qui a toute mon attention. Par ailleurs un pdf de qualité moyenne sur Gallica n’est pas la même chose qu’une transcription complete (voir Sabine page 204). Hektor (d) 13 juillet 2020 à 12:55 (UTC)Répondre
Puisque vivent les grands textes sur Wikisource, je ferai remarquer qu'un bon nombre d'auteurs de premier rang sont dans la situation suivante: mis en ligne à partir de sources diverses dès les débuts (avant 2010), ils ont été alors associés à un fac-simile et laissés dans cet état intermédiaire, d'autres ont été mis en ligne avec de grands projets (Œuvres de Blaise Pascal édition Brunschwig en 14 volumes), Œuvres complètes de Voltaire édition Garnier, Descartes, et languissent avec très peu d'ouvrages corrigés et présentés. Exemple qui m'est cher: Schopenhauer dont les ouvrages étaient en chantier depuis des années, et dont j'ai amélioré la situation avec un effort limité. Donc, invitation de ceux qui n'ont pas un auteur chéri et rare à s'intéresser aux grands auteurs (d'autant plus qu'en corrigeant on lit, et que lire ce genre de textes rend intelligent).--Wuyouyuan (d) 13 juillet 2020 à 18:39 (UTC)Répondre
- Merci pour cette discussion très intéressante! Je crois que wikisource est aussi utile pour les petits que pour les grands textes. Personnellement, je contribue à wikisource parce que wikisource ne fait pas de jugement de valeur sur les textes. Il n’y a pas de textes petits et grands: il n’y a que des textes édités et libres.
- Ces jours-ci, je corrige la Relation des quatre voyages de Christophe Colomb. Il s’agit d’un ouvrage écrit au XIXe siècle à partir des manuscrits de Las Casas à partir des manuscrits de Colomb, qu’il n'a pas jugé utile de reproduire fidèlement. Aujourd’hui, nous ne possédons pas le journal de bord de Colomb parce que personne n’a jugé utile d’en faire une copie exacte. Pourtant on pourrait arguer qu’il s’agissait d’un texte d’une importance historique.
- Aujourd’hui, sur internet, hors wikisource, je ne connais pas de site qui cherche à reproduire fidèlement les textes anciens tels qu’ils ont été édités. Wikisource est le seul site où l’on trouve des efforts de traçabilité et d’évaluation systématiques de la qualité des textes. Je pense que c’est tout particulièrement utile pour les grands textes, même si d’autres en ont déjà fait des copies approximatives ailleurs.
- Je crois qu’il convient également de reproduire les grands textes sur wikisource, même s’ils sont disponibles ailleurs, pour un effort de vulgarisation. Si wikisource ne contient que des textes rares ou peu connus, il y a peu de chances que le site touche un public au delà des experts et des passionnés (ce qui est déjà le cas, à mon sens, et c’est bien dommage).
- Et même si l’on considère que wikisource un site d’expert, wikisource permet de sourcer des éditions de références plus facilement qu’en en cherchant des copies sur Google Books, internet archive, ou autres. En cela aussi, je crois que wikisource est utile pour les grands textes. --Cassiodore89 (d) 18 juillet 2020 à 08:32 (UTC)Répondre
- Project Gutenberg a bloqué ses contenus en 2018 pour l'ensemble de l'Allemagne à la suite d'une décision judiciaire pour le moins contestable [3] ; on ignore quand Gutenberg sera à nouveau accessible aux Allemands. Un tribunal italien a ordonné en juillet 2020 le blocage du Project Gutenberg sur l'ensemble du territoire italien pour violation des droits d'auteur, décision ÀMHA téléguidée par des intérêts économiques [4] ; on ignore quand Gutenberg sera à nouveau autorisé. Des institutions françaises ont menacé de bloquer Internet Archive pour des propos prétendument terroristes [5]. J'ai appris de façon privée qu'une maison d'édition française menaçait de poursuites judiciaires le site des Classiques des sciences sociales (CdSS) parce que la maison d'édition détenait à ce moment les droits d'auteur sur les ouvrages d'un seul auteur ; c'est seulement lorsque CdSS a bloqué l'accès des Français de France aux ouvrages de cet auteur, pourtant dans le DP au Canada (pays d'hébergement des CdSS), que la maison d'édition a cessé ses menaces. La Wikiquote en français a fait l'erreur de laisser un contributeur pomper massivement des citations d'autres sites, citations pourtant dans le DP. Un tribunal français a obligé Wikiquote en français de cesser ces méfaits (violation des droits d'auteur sur les bases de données, si je suis exact) ; depuis, la communauté de cette Wikiquote linguistique exige plus d'informations sur les citations (auteur, année, ouvrage, etc.) que ce que j'ai pu observer dans d'autres sites de citations. Je connais cette situation parce que j'ai tenté d'ajouter une citation dans cette Wikiquote il y a au moins six ans. Elle a été supprimée sans avertissement parce que j'avais omis d'indiquer la page de l'ouvrage (j'ai inféré cette explication en comparant avec d'autres citations). Ce wiki a perdu un contributeur : moi, qui n'était pourtant pas novice dans l'écosystème Wikimedia. Quel est le lien avec Wikisource ? Ce wiki fait partie d'une constellation de sites dits libres. Il est plus difficile pour une maison d'édition ou un groupe d'intérêt économique d'attaquer en justice une constellation de sites Web, parce que les frais judiciaires sont proportionnels, ou presque, au nombre d'accusés. S'il y avait disons 100 sites ressemblant au nôtre, il serait inutile de s'échiner à transcrire les grands textes parce qu'ils seraient déjà publiés et que les menaces de poursuites judiciaires seraient très minces. Donc, poursuivons notre travail sur les petits et les grands textes. — Cantons-de-l'Est discuter 18 juillet 2020 à 15:03 (UTC)Répondre
Bonjour. Dans les textes anciens, on trouve souvent l'orthographe tout-à-l'heure, alors qu'aujourd'hui on écrit normalement tout à l'heure sans traits d'union. J'ai voulu ajouter cette modernisation dans Wikisource:Dictionnaire/T (tout à l heure: tout à l’heure), mais ça n'a pas l'air de marcher. Dans Don Japhet d’Arménie, les traits d'union ne disparaissent pas dans la version moderne. BrightRaven (d) 13 juillet 2020 à 12:27 (UTC)Répondre
- Bonjour, BrightRaven :la page présentant le dictionnaire de modernisation précise que les mots composés doivent être séparés par une espace, j’ai également constaté l’impossibilité de supprimer des traits d’union que ce soit dans le dictionnaire général ou dans le mini-dictionnaire créé pour une page en particulier. Le sujet a été évoqué dans la page de discussion liée au dictionnaire en 2011, sans qu’une solution ne soit trouvée.--Cunegonde1 (d) 13 juillet 2020 à 12:46 (UTC)Répondre
- Merci de cette réponse. Cependant, ça a l'air de marcher pour tout-à-fait. Je ne comprends pas pourquoi ça ne marche pas pour tout-à-l'heure. Note : j'ai bien remplacé les trait d'union et l'apostrophe par des espaces sur Wikisource:Dictionnaire/T. BrightRaven (d) 13 juillet 2020 à 12:50 (UTC)Répondre
- BrightRaven : Oui, je l’ai remarqué aussi : à partir de quatre éléments, il semble que l’expression excède les capacités de l’outil. Vous devriez essayer de faire la modification localement : par exemple, peut-être qu’insérer dans la page de transclusion
{{Modernisation|*tout à l: tout à l}} aurait l’effet voulu ? — ElioPrrl (d) 13 juillet 2020 à 14:02 (UTC)Répondre
- ElioPrrl :. Ça marche. Merci beaucoup pour cette suggestion. Je pense qu'on ne peut malheureusement pas ajouter la ligne *tout à l: tout à l dans le dictionnaire, car ça corrigerait des mots comme tout-à-l’égoût. BrightRaven (d) 13 juillet 2020 à 14:18 (UTC)Répondre
- BrightRaven : D’ailleurs je vois que vous utilisez
{{sic2}} chaque fois qu’un mot diffère de l’orthographe actuelle ; dans des éditions de cette époque (en gros, jusqu’au début xxe siècle), je pense que vous pouvez vous en passer, puisque, pour l’époque, cette graphie n’a rien d’une erreur ou d’une coquetterie d’auteur : le modèle {{Modernisation}} suffit, et, si vous le souhaitez, par précaution, une précision dans la discussion de l’index avec le modèle {{ChoixEd}}. Voyez par exemple les Fables de La Fontaine. Si par contre, un texte de 1920 écrivait toujours les imparfaits en -oit, par exemple, cela serait tout à fait justifié. — ElioPrrl (d) 13 juillet 2020 à 14:20 (UTC)Répondre
- La modernisation .... Dans un texte de Émile Littré (1801-1881), sur le Latin mérovingien, quelqu'un a voulu moderniser les mots carlovingien en carolingien et visigots en wisigots. Comme quoi, pour des âmes simples, l'ancien temps s'étend jusqu'à Napoléon III et le vocabulaire scientifique de ce temps-là est si périmé que cela gêne la lecture. Il serait bon de se rappeler que la modernisation vise à reposer le lecteur qui aurait du mal avec le ſ et avec les imparfaits d'avant la Révolution. Mais l'assurance intellectuelle de nous autres contributeurs est sans limite. J'ai trouvé une correction au mot "ente" (du verbe "enter", greffer) dans le Discours de la servitude volontaire, de La Boétie. --Wuyouyuan (d) 14 juillet 2020 à 07:26 (UTC)Répondre
- Il me semble que le modèle
{{sic2}} est utile, pour éviter qu'un autre contributeur prenne une orthographe ancienne pour une coquille. (Un imparfait en -oit a peu de chance d'être pris pour une coquille, mais âme ou théâtre sans accent circonflexe peuvent facilement être confondus avec une coquille.) Par ailleurs, cela me permet de rapidement vérifier la modernisation sur la page de transclusion, car les mots à corriger apparaissent ainsi en vert. Je pense également que la modernisation devrait strictement se limiter à des changements d'orthographe. Moderniser quantesfois en combien de fois me semble abusif. BrightRaven (d) 14 juillet 2020 à 07:34 (UTC)Répondre
- Pour cette vérification, je me contente de l’option montrer les altérations ; je trouve assez indigestes tous ces mots en vert qui n’ont pas été mis en évidence par l’auteur. Quant au reste @BrightRaven et @Wuyouyuan, vous avez tout à fait raison ; on doit s’en tenir à des changements graphiques, à la limite phonétiques (dit-on pour dit-l’on, portrait pour pourtrait), mais certainement pas s’engager dans des changements lexicaux (et encore ! il est des occurrences où il vaut mieux garder la graphie originelle : archaïsmes volontaires, et ce dès la xvie siècle par exemple avec La Fontaine, mots placés à la rime ou importants pour le décompte des syllabes, etc.). Quant à la date, je crois qu’on peut encore moderniser l’orthographe de textes bien postérieurs à la réforme de 1835 : signalons qu’à ma connaissance, en 1915 encore, la Revue des Deux Mondes orthographiait -ns les pluriels des mots en -nt — alors que les auteurs qui y contribuaient (pour Barrès, j’ai même pu le vérifier sur des lettres manuscrites) n’écrivaient plus ainsi depuis longtemps… — ElioPrrl (d) 14 juillet 2020 à 20:09 (UTC)Répondre
Bonjour,
nous travaillons à plusieurs sur Livre:Description de l'Égypte (2nde édition - Panckoucke 1821), tome 1, Antiquités - Description.pdf et je travaille sur le sommaire. Le truc, c'est que la table des matières présente des chapitres et des paragraphes, mais je ne sais pas à quel niveau transclure. Dois-je faire des sous-pages par chapitre ou par paragraphe ?
À +, Lepticed7 (Viens tcharer ! :D) 13 juillet 2020 à 12:37 (UTC)Répondre
- Et il y a aussi un niveau intermédiaire de sections. À mon avis, un découpage fin se justifie lorsque le texte en question a de l’intérêt séparément des autres composantes de l’ouvrage (exemple : un poème dans un recueil). En l'occurrence, j'ai l'impression que les paragraphes sont des divisions un peu arbitraires d'une section qui décrit un site donné (avec un auteur qui varie d’une section à l’autre). Donc c’est plutôt au niveau de la section que je ferais le découpage. Les transclusions seront un peu grandes, certes. Seudo (d) 13 juillet 2020 à 12:56 (UTC)Répondre
- Lepticed7 : Tout à fait d’accord avec Seudo (d · c) ; et ensuite, pour faciliter la navigation, rien ne vous empêche de créer dans votre transcription des ancres pour chaque paragraphe, et d’y renvoyer dans la table des matières. C’est par exemple ce que j’ai fait pour les fragments individuels groupés sous une même rubrique dans le Théâtre en liberté d’Hugo. — ElioPrrl (d) 13 juillet 2020 à 14:09 (UTC)Répondre
- Lepticed7 :
- à placer dans l'espace Page:
{{ancre|De la route qui conduit de Syène à l'île de Philæ}}- à placer dans le sommaire
[[Description de l’Égypte (2nde édition)/Tome 1/Chapitre I#De la route qui conduit de Syène à l'île de Philæ|De la route qui conduit de Syène à l'île de Philæ]]
- Modèle utilisé :
{{Ancre}}
- Assassas77 (d) 13 juillet 2020 à 17:24 (UTC)Répondre
À force de lire et transclure des livres du xixe siècle ou du début du vingtième je m'aperçois qu'il arrive parfois — je ne dirais pas que c'est courant — de ne pas avoir de marqueur « première partie », mais par contre d’avoir une page deuxième (ou seconde selon les cas) partie puis troisième partie, etc. Dès lors, faut-il remettre un « première partie » dans nos transclusions ? Est-ce une modernisation justifiée ?Hektor (d) 13 juillet 2020 à 13:59 (UTC)Répondre
- Hektor : il y a quelque temps je vous aurais probablement répondu oui sans hésiter — et c'est en partie encore mon avis — mais j'en viens à me demander si au fond ce genre d'ajout/modification est vraiment nécessaire. Quand le lecteur lira les mots Seconde partie, il sera clair que ce qu'il a lu auparavant était la première, indépendamment que ce soit signalé ou non, et probablement que les lecteurs du livre sous format papier n'allait pas vérifier que Première partie était bien écrit. Si vous pensez toutefois que ça a une réelle valeur informative pour le lecteur (ce qui se défend), il me semble qu'il faut d'une part le signaler quelque part (en discussion de la page/du livre) et plutôt le entre balises includeonly. --Jahl de Vautban (d) 13 juillet 2020 à 14:29 (UTC)Répondre
- Sur un livre papier, la mention "première partie" n'est pas indispensable si la "deuxième partie" est annoncée au bon entroit ; mais dans un livre numériue, que le lecteur ne peut feuilleter qu'en utilisant la table des matières, j'insère une page ou une entête "première partie" pour que la table des matières donne la structure de l'ouvrage. --Wuyouyuan (d) 14 juillet 2020 à 07:33 (UTC)Répondre
Vous êtes invités à procéder aux essais du modèle {{Pointsdesuite}} puis à l’ajouter à votre coffre à outils. Comme mentionné par Viticulum, le modèle {{Table}} devrait être réservé strictement à la confection des Tdm car une partie importante de l’information n’est pas exportée (notamment les « Dots » et le contenu du paramètre Page). Invitation particulière lancée à ceux qui possèdent des liseuses. --Denis Gagne52 (d) 15 juillet 2020 à 00:19 (UTC)Répondre
- Un exemple de ce que l’on peut obtenir facilement : ici. Personnellement, j’aimerais avoir un petit espace entre le texte de gauche et le début des points.
- Dans la documentation du modèle, tu pourrais faire référence au modèle filet, sous la rubrique Voir aussi. Merci pour ce modèle. --JLTB34 (d) 15 juillet 2020 à 06:01 (UTC)Répondre
- Comparaison entre les anciens points et les nouveaux points ici Hektor (d) 15 juillet 2020 à 09:58 (UTC)Répondre
- JLTB34 : je peux prévoir un espace minimal de 4px et je vais ajouter le référence au modèle filet. Merci.
- Hektor : Le modèle Table utilise plutôt un tireté construit à partir de la bordure d’un div. Voir la possibilité d’inclure des motifs de points de suite (peut-être avec un paramètre du genre m=1,2,3, etc). Modèle:Pointsdesuite/Banc d’essai. Il faudrait en choisir quelques-uns.--Denis Gagne52 (d) 15 juillet 2020 à 12:35 (UTC)Répondre
- D’après les manuels de typographie ou de composition que j’ai trouvés (Brun 1825, Desormes 1888, Marcassin 1900, Cim 1905, Pernin 1957), dans une table, les gros points (car j’ai appris que tel est leur nom ; plus rarement points de conduite), sont fondus sur un espace d’un demi-cadratin (i.e. 0.5em en termes CSS), et doivent s’interrompre en laissant un espace double de leur espacement (donc 1em dans ce cas) avant le contenu auquel ils mènent ; de ligne à ligne, les gros points sont alignés les uns sous les autres, ce pour quoi on insère une espace justifiante entre le dernier mot et les gros points eux-mêmes. Enfin, il existe une variante des gros points (dits points carrés), fondus sur cadratin cette fois-ci, utilisés sur toute une ligne pour signaler une lacune importante dans un texte ; on peut (mais rarement) les utiliser dans un tableau, en les arrêtant donc 2em avant le texte qui leur fait face. Malheureusement, je ne sais s’il vous est possible, @Denis Gagne52, d’implémenter ces mesures traditionnelles en CSS, ou s’il faudra se contenter de pis-aller. — ElioPrrl (d) 15 juillet 2020 à 13:59 (UTC)Répondre
- Denis Gagne52 : j’ai un cas d’utilisation où le rendu ne m’apparaît pas correct. Il est corrigeable en utilisant d’autres paramètres (comme ld=…)
- Dans le cas des "Huîtres", le texte à droite est trop long, mais je m’attendrais à ce que le paramètre largeur totale soit prépondérant (ici, 80%), et que ce soient les points de suite qui soient diminués. Qu’en penses-tu ? --JLTB34 (d) 15 juillet 2020 à 13:45 (UTC)Répondre
- JLTB34 : Je ne crois pas qu’il soit sage de déborder à gauche. Par défaut, 4em sont attribués au texte de droite et le reste du 80% est réservé aux points de suite et au texte de gauche qui occuperont une 2e ligne si nécessaire. Si le premier texte occupe la presque totalité de l’espace qui lui est alloué (ex: 79% - 4em), alors le texte de gauche qui déborde va se superposer au premier. Je ne vois pas comment on pourrait éviter cette collision sinon qu’en respectant la limite qui les sépare. Désolé mais, pour le moment, je ne vois que l’option de déborder à droite ou de tronquer.
- Ex.:
Huîtres, Houblon, Homard et Irish-Stew
- Merci à @JLTB34,@ElioPrrl,@Viticulum,@Hektor et @Jahl de Vautban. SVP vérifier si la liste de vos demandes ou commentaires est complète. Je tenterai de tout corriger dans la même opération. À moins que la communauté en décide autrement, le motif par défaut sera celui qui se rapproche le plus de ce qui est préconisé dans les manuels consultés par ElioPrrl. --Denis Gagne52 (d) 15 juillet 2020 à 19:33 (UTC)Répondre
- Liste des nouveautés
{{Pds}} v. 0.2
-
- mode simple ligne : découpage automatique des points de suite à .25em des textes. Toutefois Attention aux collisions ;
- mode multiligne : obtenu en attribuant une largeur au texte de droite ld. Si la valeur de ld est insuffisante le texte de droite débordera à droite ;
- espacement entre les points en em : défini par x compris entre .3 et 1 ;
- motif pour les situations délicates : obtenu en ajoutant m = fin ;
- points de suite dessinés et positionnés en utilisant l’unité de mesure em de façon à s’ajuster à la taille de la police du parent html.
- Surtout ne pas hésiter à améliorer la documentation ni à commenter. --Denis Gagne52 (d) 16 juillet 2020 à 20:00 (UTC)Répondre
Bonjour. Je corrige un livre qui contient des notes de bas de page signées. La signature apparaît à droite de la dernière ligne de la note (avec un alinéa à droite). Pour l’instant, j’ai utilisé le modèle Droite, mais il fait apparaître la signature à la ligne suivante, avec un espacement entre les lignes. Y a-t-il une solution élégante (sans ajouter d’espaces à la main) pour présenter la signature comme dans l’œuvre originale ?
Exemple ici: https://fr.wikisource.org/wiki/Page:De_Navarrete_-_Relations_des_quatre_voyages_entrepris_par_Christophe_Colomb,_Tome_2.djvu/35
Merci! --Cassiodore89 (d) 18 juillet 2020 à 07:30 (UTC)Répondre
- Bonjour @Cassiodore89 ! Il existe le modèle
{{FlotteADroite}} qui devrait vous convenir exactement ; son seul défaut étant qu'il n'est pas possible de contrôler l'indentation à droite. --Jahl de Vautban (d) 18 juillet 2020 à 08:06 (UTC)Répondre
- Merci @Jahl de Vautban! C’est parfait. Il semble que l’on puisse même contrôler l’indentation à droite avec l’option |marge=X%. --Cassiodore89 (d) 18 juillet 2020 à 08:40 (UTC)Répondre
- Effectivement, je ne l'avais jamais remarqué ! --Jahl de Vautban (d) 18 juillet 2020 à 08:43 (UTC)Répondre
Bonjour chères Wikisourcières et chers Wikisourciers, je suis en train de me lancer sur un projet d’ampleur sur les dictionnaires et les encyclopédies. En effet, actuellement c’est le bazar le plus complet autant dans les catégories que dans les pages du projet en place. Je m’apprête donc à :
- Refaire entièrement la catégorisation de ces ouvrages d’après celle que j’ai défini dans mon projet (des sous-catégories plus fines existeront en dessous néanmoins, et je suis preneur de retours si vous pensez que je vais dans le mur)
- Simplifier et organiser les pages du projet (comme le catalogue et la page d’avancement, idem si vous avez des retours et/ou des besoins)
- Virer les pages inutiles du projets (certaines ne sont que des transclusions des autres, idem si vous avez des retours et/ou des besoins)
- Souffler un peu
- Prendre un thé
- Commencer à rechercher des fac-similés d’ouvrages non-présent encore ici et les verser
- Entamer la relecture de tout ça
- Faire de Wikisource la plus grand banques de dictionnaires et d’encyclopédie francophone
- Verser tout ce qui manque dans le Wiktionnaire
- Devenir maître du monde de la lexicographie
- Reprendre un thé
Merci d’avance pour vos retours, vos gardefous et pour votre aide, si participer à ce projet vous intéresse. Lyokoï (d) 19 juillet 2020 à 11:47 (UTC)Répondre
- Lyokoï :
- Bonjour, déjà je te souhaite un bon courage pour ce travail de moine
- Maintenant j’avais créée cette page Utilisateur:Le_ciel_est_par_dessus_le_toit/test_dicos où l’on trouve tous les dicos présent sur wikisource (à la date de dernière modification de la page), à vrai dire c’est un ménage effectué à partir de la page d’avancement du projet dico créée par Pybwiki. Peut-être que cette page peut être utile. Concernant les dicos j’ai déjà fait beaucoup de ménage, mais la tache étant ardue, j’ai vite désespéré.
- Tu dois pouvoir trouver des liens vers les fs en page de discussion. je me rappelle en avoir ajouter à une période, sans pouvoir dire combien.
- Pour les catégories, il ne suffit pas de les bleuir mais il faut vérifier aussi si elle sont pertinente !
- Si tu as besion d’un couop de main pour la recherche de fs entre autre, je suis partant à condition que tu ne sois pas trop pressé. Mes projet hors WS me prennent beaucoup de temps en ce moment.
- Par contre je pense que tu devrais remplacer le thé par le café, pour rester éveillé
- --Le ciel est par dessus le toit Parloir 19 juillet 2020 à 12:11 (UTC)Répondre
- Le ciel est par dessus le toit : Merci pour le soutien ! Et merci pour ton lien ! Je vais m’en servir pour le projet.
- Concernant les fs, c’est pas pour tout de suite, mais dès que ce sera le cs, je penserais à toi ! Lyokoï (d) 19 juillet 2020 à 16:10 (UTC)Répondre
- Dictionnaires et encyclopédies ... Quand j'en entends parler, je repense au Dictionnaire de Trévoux en chantier (sérieux, avec des contributeurs de poids) depuis 2010 et qui en est au 2e tome sur huit. Ou à mes nombreux atterrissages de recherche sur des ouvrages vides, dont je me console en contemplant le fac-simile (feuilleter un DJVU dans les conditions de Wikisource à la recherche de quelque chose n'est pas une pure joie). L'idée de relancer l'afflux de ces plantes mortes ne m'enthousiasme pas tant que ça. --Wuyouyuan (d) 23 juillet 2020 à 15:01 (UTC)Répondre
- Wuyouyuan : Bein l’idée de ce projet c’est aussi de relancer la transcription de ces ouvrages… Par contre j’ai pas compris ta phrase « L'idée de relancer l'afflux de ces plantes mortes ne m'enthousiasme pas tant que ça. ». Tu peux expliciter ? :) Lyokoï (d) 24 juillet 2020 à 08:41 (UTC)Répondre
- Jusqu'ici, le fléau des dictionnaires qui prolifèrent et restent avec la moitié de la lettre A lisible (dans un bon cas) mais qui sont déclarés dans l'espace principal et polluent les résultats des moteurs de recherche restait limité au zèle d'un contributeur. Avec une structure qui a l'air sérieuse d'autres risquent d'avoir l'idée de contribuer, avec le même genre de résultat. Quant à la transcription, voir plus haut le dictionnaire de Trévoux; c'est trop volumineux.--Wuyouyuan (d) 24 juillet 2020 à 09:51 (UTC)Répondre
- « Le fléau », mais en fait, on sait pas trop… J’aimerais savoir en effet où est-ce qu’on en est. Ça pourrait permettre aussi à peut-être proposer de déplacer tout ça dans un espace de nom dédié pour ne pas la recherche dans les textes. Mais tant qu’on n’en a pas l’ampleur difficile d’estimer la tâche. Pour le Trévoux, je ne pense pas que ce soit trop volumineux, c’est juste long, mais c’est pas comme si on le savait… Des ouvrages comme le dictionnaire des dictionnaires de 3 colonnes en 8 tomes sur des pages grands format me font plus peur. Mais bon, Wikisource est bien arrivée à bout de l’encyclopédie de Diderot et Dalambert ! :) Lyokoï (d) 30 juillet 2020 à 14:12 (UTC)Répondre
- Bon courage dans ce travail de titan ! --Jahl de Vautban (d) 25 juillet 2020 à 20:45 (UTC)Répondre
- Merci Beaucoup pour ton soutien ! ;) Lyokoï (d) 30 juillet 2020 à 14:12 (UTC)Répondre
- Lyokoï :
- Je viens juste de lire ton avis et ta question, je viens rarement en ce moment. Bonjour, déjà je te souhaite un bon courage pour ce travail de moine peut-on lire plus haut ! Je m'associe pleinement à ton désir, mais pour le moment je dispose de très peu de temps libre. Le Trévoux, c'est lent, mais bon, ça ne recule pas ! Et quand ce sera fait ça rendra bien service. Ce que tu entreprends est un énorme chantier et j'essaierai volontiers de donner un coup de main dès que du temps se libéreras, selon mes compétences. Je crois que ça fait longtemps que tu mijotes ce projet et c'est en connaissance du dossier que tu te lances ! Alors 1000x bravo. --Acer11 (d) 23 août 2020 à 20:00 (UTC)Répondre
- Acer11 : Merci pour le soutien ! Le Trévoux est un travail considérable mais vraiment très bien fait et je m’en suis beaucoup inspiré. La structuration va me prendre un peu de temps, et l’aide ne sera pas de refus, mais je vais y aller mollo, l’important étant que ce soit bien fait pour les contributions futures soient plus faciles. :) Lyokoï (d) 24 août 2020 à 10:21 (UTC)Répondre
Bonjour. Il arrive fréquemment qu'un périodique ayant du repoussé d'une année un volume indique deux dates comme année d'édition (exemple où l'année d'édition est 1915-1916). Or l'espace Livre ne permet pas d'entrer une date avec un tiret ; je me suis résolu à mettre un point, mais ça ne me paraît pas optimal. Quelqu'un aurait-il une solution ? --Jahl de Vautban (d) 20 juillet 2020 à 11:03 (UTC)Répondre
Dans le même ordre d’idées, je trouve très insatisfaisant le mode d’affichage des dates de publication originale dans les boîtes de titre. Par exemple je dispose d’une édition du Protagoras de Platon à la CUF datée en page de titre de 1955 ; la première édition remonte à 1923 ; j’obtiens alors en boîte de titre : Platon — Protagoras (1923) — Texte établi […], Les Belles Lettres, 1955. Avouez que pour un texte du ive siècle siècle avant J.-C., voir ainsi cette date accolée au titre et au nom d’auteur, ça fait un peu bizarre ; on dirait que Platon est un contemporain de Bergson ! À mon sens, l’indication de la date à la suite du titre est intéressante pour distinguer deux versions d’une même œuvre (mettons, Paul Claudel — Tête d’or (1890) à distinguer de Paul Claudel — Tête d’or (1894), la pièce ayant connue deux rédactions très différentes). Je pense qu’il vaudrait mieux afficher quelque chose comme cela se fait usuellement dans les bibliographies : Platon — Protagoras — Texte établi […], Les Belles Lettres, 1955 [1923] ou 1923 (éd. 1955), en reléguant toutes les informations strictement éditoriales au même endroit, sans les mêler aux données qui ne varient pas d’une édition à l’autre comme le titre ou le nom d’auteur. — ElioPrrl (d) 20 juillet 2020 à 17:23 (UTC)Répondre
- Platon — Protagoras — Texte établi […], Les Belles Lettres, 1923 (éd. 1955) : oui, plus précis je trouve. Avis des Wikisourciens ?
Auteur_-_Titre,_Éditeur_Scientifique,_Maison_d'édition,_Date,_Tome.djvu
- deviendrait :
Auteur_-_Titre,_Date,_Éditeur_Scientifique,_Maison d'édition,_(Date_édition),_Tome.djvu
- C'est bon ?
- --Zyephyrus (d) 22 juillet 2020 à 08:13 (UTC)Répondre
- Zyephyrus : Désolé, je n’ai pas été assez clair, et il doit y avoir méprise. Ce n’est pas le nom des fichiers qui me dérange (pourvu qu’un fichier comporte le nom de l’auteur et le titre et que deux fichiers ne portent pas le même nom, cela me convient parfaitement). C’est la boîte de titre, qu’on paramètre avec header, en transclusion ; dans mon exemple, on obtient des choses du genre :
- auxquelles je préférerais, en distinguant bien les informations sur l’œuvre des informations sur l’édition :
- ou quelque chose d’équivalent (1955 [1923], 1955 [1923¹], 1923 (rééd. 1955), etc.). — ElioPrrl (d) 22 juillet 2020 à 09:12 (UTC)Répondre
- Ah, autant (au temps ?) pour moi, j'avais en effet mal compris. Je trouve ta proposition très intéressante elle aussi !
- Serait-il ou non logique de préciser « établi par » avant « traduit par », et si oui, comment présenter la boîte de titre ? Est-ce que l'ensemble serait confus ? --Zyephyrus (d) 22 juillet 2020 à 10:13 (UTC)Répondre
- Zyephyrus : Effectivement, ce serait aussi plus logique (la formule habituelle est bien Texte établi et traduit par…, et pas l’inverse), et on pourrait tout faire en même temps. Seulement je n’ai aucune idée d’où est codée cette boîte de titre. Je proposerais en tout cas quelque chose dans ce genre, si j’avais tout à refaire :
- avec la date de rédaction seulement si elle a quelque intérêt (rédactions successives d’une même œuvre). Et ce pour les livres uniquement ; je ne me suis pas encore frotté aux recueils et aux journaux, à voir si j’aurais des modifications à faire. — ElioPrrl (d) 22 juillet 2020 à 10:33 (UTC)Répondre
- PS : Quant aux conventions de nommage, comme je disais, je n’ai rien à opposer ni au maintien des règles actuelles, ni à leur changement. Je laisse les autres juges de l’intérêt d’une modification. — ElioPrrl (d)
{{InfoTitre}} : ce modèle est-il suffisant pour les compléments que nous ajoutons ? Placer un navigateur simplement en pied de page ? Et, d'autre part, faut-il rapprocher les couleurs à employer de celles du scriptorium ? --Zyephyrus (d) 23 juillet 2020 à 15:54 (UTC)Répondre
- Zyephyrus : De ce que disent les documentations, tous ces modèles (
{{InfoTitre}}, {{Chapitre}}, {{ChapitreNav}}, etc.) sont destinés aux textes sans facsimile associé. Il s’agirait plutôt de modifier Module:Header_Template, qui utilise directement les informations de la page d’index ou celles précisées manuellement avec <pages index= />; cela permettrait ainsi de modifier les pages déjà existantes. Mais je ne saurais pas le faire moi-même, ou alors à vos risques et périls ! Attendons peut-être d’autres avis — ElioPrrl (d) 23 juillet 2020 à 16:10 (UTC)Répondre
Bonjour,
Pour des raisons visiblement complexes de sécurité (je vous laisse lire en détail les explications sur le ticket phab:T257066), l'extension mw:Extension:Score - qui sert à retranscrire les partitions et notations musicales - a été désactivée il y a quelques jours et pour une durée indéterminée.
Les partitions existantes sont toujours visibles mais les nouvelles ou les anciennes modifiées n'apparaissent plus (tant que le problème n’est pas corrigé), il vaut donc mieux éviter de modifier les partitions existantes pendant quelques temps . À la place, il y a un message d'erreur « Musical scores are temporarily disabled. » (voir sur Page:Le Toucher, nouveaux principes élémentaires pour l'enseignement du piano, Marie Jaëll.pdf/22 - trouvé grâce à Tambuccoriel : - ou parfois le message Could not execute LilyPond: /dev/null is not an executable file. Make sure $wgScoreLilyPond is set correctly.).
Cdlt, VIGNERON (d) 20 juillet 2020 à 17:24 (UTC)Répondre
- Ce que je propose n'est pas top, mais c'est mieux que d'attendre la réactivation de Score (même s'il est utilisé dans Wikipédia). Les partitions pourraient être transcrites dans MuseScore, un logiciel open source. Les partitions pourraient ensuite être exportées aux formats PNG pour l'écrit et Ogg Vorbis pour l'exécution musicale. On peut même exporter la partition complète au format txt (que le logiciel déguise sous le format mscx). — Cantons-de-l'Est discuter 22 juillet 2020 à 01:51 (UTC)Répondre
- Cantons-de-l’Est :, je me suis toujours abstenu de faire des partitions sur WS, car je ne comprenais rien au code. Avec Musescore, que j’utilise très souvent cela me parait effectivement plus simple, au moins pour la retranscription des notes. La proposition me paraît en tout cas digne d’être étudiée. --Le ciel est par dessus le toit Parloir 22 juillet 2020 à 08:10 (UTC)Répondre
- Le jpg à 80% est plus adapté que le png, encore trop lourd même au plus fort de sa compression.Cobalt3d (d) 23 juillet 2020 à 13:46 (UTC)Répondre
- Cantons-de-l'Est, Le ciel est par dessus le toit et Cobalt~frwiki : l'idée est intéressante mais il faudrait aussi faire un export au format Lilypond en prévision de la réactivation de l’extension. Cdlt, VIGNERON (d) 24 juillet 2020 à 09:59 (UTC)Répondre
- Quelqu’un a-t-il un exemple ? et/ou un lien vers une page de démonstration ? Les partitions exportées doivent être sauvées sur Commons ? Les fichiers audio en ogg aussi ? Et au final la page ne peut pas être validée ?? --JLTB34 (d) 24 juillet 2020 à 12:57 (UTC)Répondre
- Salut JLTB34 : En voici deux que tu pourrais peut-être valider par la même occasion. :-)
- Le compte n’y était pas pour certaines mesures et je ne suis pas certain d’avoir bien reproduit un symbole. On peut aussi utiliser Frescobaldi pour produire les fichiers jpg et ogg ce qui permet d’ajouter un bloc Score en commentaire. --Denis Gagne52 (d) 26 juillet 2020 à 03:52 (UTC)Répondre
- Denis Gagne52, VIGNERON et Cantons-de-l’Est : (et autres)… Ne faudrait-il pas ajouter une catégorie pour ces pages avec score/jpg/ogg, de sorte que lorsque l’extension score sera remise en service, on puisse "nettoyer" le surplus ? --JLTB34 (d) 27 juillet 2020 à 05:17 (UTC)Répondre
- JLTB34 : oui, excellente idée ! Selon le ticket phabricator, l'extension devrait être partiellement ré-activée la semaine prochaine et complètement dans les semaines suivante. Cdlt, VIGNERON (d) 27 juillet 2020 à 07:35 (UTC)Répondre
- Bonne idée en effet. Comme il s’agit d’une situation temporaire, on pourrait aussi se servir de la Catégorie:Partitions à transcrire qui ne comprend que très peu d’items ? --Denis Gagne52 (d) 27 juillet 2020 à 14:17 (UTC)Répondre
- Denis Gagne52 et VIGNERON : Oups ! J’ai été trop vite, j’ai (déjà) créé la catégorie catégorie:page avec score inactif. L'idée de la Catégorie:Partitions à transcrire est tout aussi bonne… --JLTB34 (d) 28 juillet 2020 à 06:04 (UTC)Répondre
Tambuccoriel, Cantons-de-l'Est, Le ciel est par dessus le toit, Denis Gagne52 et JLTB34 : et le problème est (au moins partiellement) résolu, certaines fonctions peuvent ne pas pleinement fonctionner mais cela devrait rapidement complètement revenir à la normale. Cdlt, VIGNERON (d) 30 juillet 2020 à 07:36 (UTC)Répondre
Bonjour, depuis quelques temps, l'import automatique des données d'un livre sur wikidata depuis wikisource ne fonctionne plus pour moi. Lorsque je colle le nom de la page principale dans la boite de dialogue, l'engin mouline, puis apparaît un message Convertion to Wikidata failed: "error", et enfin une boite de dialogue "Quelque chose s'est mal passé, fermer/réessayer". Exemple d'hier, vous pouvez essayer ici. Certains d'entre vous ont-ils rencontré le même problème ?--Cunegonde1 (d) 23 juillet 2020 à 05:26 (UTC)Répondre
- Cunegonde1 (d · c), Quelque chose m'échappe dans votre message. Vous cherchez le titre de l'ouvrage sur Wikidata ? Vous souhaitez voir le lien Wikidata dans [6] ? Ou bien vous cliquez sur la loupe Wikidata dans [7] et Wikidata ne renvoie rien ? — Cantons-de-l'Est discuter 23 juillet 2020 à 18:55 (UTC)Répondre
- Cantons-de-l'Est : Merci de ton aide. Mon message manque en effet de clarté, je m'explique :
- J'ai transcrit un ouvrage (Anecdotes pour servir à l'histoire...) dans Wikisource.
- Je souhaite l'ajouter comme nouvel item à Wikidata.
- J'ouvre Wikidata, crée un nouvel item et y ajoute le titre de l'ouvrage dans la première case de la page Wikidata.
- Je vais dans le bandeau de gauche et je clique en bas sur l'avant dernier lien "import Wikisource page".
- Je renseigne la boîte de dialogue idoine avec le nom de l'ouvrage transcrit (le nom de la page principale).
- A ce moment le problème décrit plus haut se produit.
- Auparavant en utilisant la même procédure (je crois) cela fonctionnait et les données renseignées sur Wikisource étaient automatiquement transférées dans Wikidata, il n'y avait qu'à rajouter les information de copyright et de source. C'est plus pratique que de tout renseigner manuellement. J'ai bien sûr essayé de trouver le problème dans l'aide de Wikidata, sans succès.--Cunegonde1 (d) 24 juillet 2020 à 05:45 (UTC)Répondre
- Cunegonde1 : je ne dispose pas de ce bouton. Est-ce un gadget ou un script ? --Jahl de Vautban (d) 24 juillet 2020 à 06:02 (UTC)Répondre
- Jahl de Vautban : Merci de ton aide. Le lien se trouve dans en bas de la section outils sur la page de l'item. J'ai épluché mes préférences sur Wikidata et ne trouve pas laquelle active cet outil.--Cunegonde1 (d) 24 juillet 2020 à 06:19 (UTC)Répondre
- Cunegonde1 : trouvé. Tu as dans ton common.js un script de Tpt. Le mieux est sans doute de voir avec lui ce qui peut clocher. --Jahl de Vautban (d) 24 juillet 2020 à 06:38 (UTC)Répondre
- Jahl de Vautban :, Ouaou ! quel détective ! Merci infiniment, j'avais complètement oublié cet ajout qui je crois m'avait été conseillé par Hélène ou un autre contributeur ??? Mémoire et confinement ne font pas bon ménage. Bref je vais contacter Tpt--Cunegonde1 (d) 24 juillet 2020 à 07:43 (UTC).Répondre
- Cunegonde1 : Le script s’attend peut-être à trouver une page auteur dans Ws qui réfère à un élément Wikidata en l’occurence anonymous, ou anonyme. S’il le recherche directement dans Wd, il ne le trouvera pas car tu as utilisé une lettre capitale dans l’espace livre. Il faudrait p-e ajouter anonyme également connu comme Anonyme dans Wd et créer un équivalent dans Ws. --Denis Gagne52 (d) 24 juillet 2020 à 12:09 (UTC)Répondre
- Denis Gagne52 : Merci de ton aide. J’ai supprimé le nom d’auteur (anonyme) dans l’espace livre, ainsi que sur Common et cela ne résout malheureusement pas le problème J’ai également essayé de mettre anonyme dans l'espace livre, toujours sans succès.--Cunegonde1 (d) 24 juillet 2020 à 12:52 (UTC)Répondre
- L'erreur était un problème de permission CORS liés au changement d'URL qui a eu lieu sur tools.wmflabs.org (et qui avait aussi cassé l'outil d'export ePub). C'est maintenant corrigé. Tpt (d) 24 juillet 2020 à 21:09 (UTC)Répondre
- Tpt : Merci beaucoup.--Cunegonde1 (d) 25 juillet 2020 à 05:00 (UTC)Répondre
Bonjour à tous,
Je bataille avec la page 229 du Charme de l’Histoire. L'auteur y a inséré une note de bas de page qui s'étend sur plusieurs pages (jusque là pas de problème) et à l'intérieur de laquelle il y a à nouveau une note (là ça devient costaud). Sur ce coup-là, aucune des solutions proposées par l’aide ad hoc ne me satisfait. Je me suis rabattu sur la solution N°1, mais qui est loin d'être satisfaisante. Si quelqu'un a une meilleure idée je suis preneur ! --Laurent Jerry (d) 23 juillet 2020 à 13:02 (UTC)Répondre
- Pourquoi pas la solution 3 que je viens de mettre en oeuvre [8]. Certes, en transclusion cela posera un problème, mais il suffit de déplacer la sous-note et de la mettre à la fin de la note en page suivante et cela devrait fonctionner. Seudo (d) 23 juillet 2020 à 13:19 (UTC)Répondre
- Je pense que cela doit pouvoir se gérer à coups de noinclude et includeonly. Hektor (d) 23 juillet 2020 à 13:39 (UTC)Répondre
- Seudo et Hektor : merci beaucoup ! J'ai essayé de mettre la note page 229 entre balises noinclude, et de la reproduire page 230 entre balises includeonly, mais ça ne fonctionne pas. Encore un truc que j'ai raté, je crois… --Laurent Jerry (d) 23 juillet 2020 à 13:40 (UTC)Répondre
- Seudo et Laurent Jerry : Je voulais dire, mettre les deux pages completes 229 et 230 en noinclude et refaire une page fusionnée 229-230 ensuite sur la même page 230 avec la note sur une seule page également avec sa note de second niveau. Hektor (d) 23 juillet 2020 à 13:51 (UTC)Répondre
- Laurent Jerry et Hektor : Je crois que les balises includeonly et noinclude ne fonctionnent pas à l’intérieur d’une note, il me semble qu’on en a déjà parlé ici. Personnellement, je ne les utiliserais pas du tout, en expliquant sur la page de discussion pourquoi le texte de la sous-note est sur la seconde page et pas sur la première (tant pis pour le rendu en mode Page, qui est moins important que la transclusion). Mais on peut aussi dupliquer la note sur chacune des deux pages en la mettant d’une part à l’intérieur d’un includeonly (et non l’inverse), d’autre part à l’intérieur d'un noinclude avec le contenu adéquat… Seudo (d) 23 juillet 2020 à 13:54 (UTC)Répondre
- Seudo et Laurent Jerry : Jetez un coup d’œil à ce que j’ai fait. Je crois que j’y suis presque… Hektor (d) 23 juillet 2020 à 14:16 (UTC)Répondre
- Ca a l’air correct sur le rendu… quoiqu’un peu compliqué à gérer pour les corrections ultérieures. Seudo (d) 23 juillet 2020 à 14:20 (UTC)Répondre
- On peut toujours mettre un petit mot d'explication sur la page de discussion. Hektor (d) 23 juillet 2020 à 14:24 (UTC)Répondre
- Ceci dit je préfère éviter les solutions bestiales s’il y a une alternative élégante ; donc si les auteurs du tutoriel sur les notes peuvent nous faire une explication sur comment on fait pour une note dans une note quand la première note est sur plusieurs pages, ils sont les bienvenus… Hektor (d) 23 juillet 2020 à 16:04 (UTC)Répondre
- Je retrouve ceci dans notre Trousse à outils, mais je ne sais plus ce que c'est :
- {{#tag:ref|blabla<ref>blabla</ref>|nomdelanote}}
- Est-ce utilisable ? --Zyephyrus (d) 24 juillet 2020 à 11:49 (UTC)Répondre
- C’est bien ce qu'a fait Laurent Jerry (d · c · b), mais l'inconvénient est que la sous-note apparaît avec le même style de numérotation que la note principale, et en plus avant celle-ci. Seudo (d) 24 juillet 2020 à 11:57 (UTC)Répondre
- Et ceci, mêmes inconvénients ? --Zyephyrus (d) 24 juillet 2020 à 12:10 (UTC)Répondre
Bonjour,
Je suis en train de lire en epub/mobi Les Mystères de Paris, et je constate qu'il y a un problème avec les liens vers les notes dans plusieurs parties. Elles ne fonctionnent pas en epub/mobi (en pdf cela semble correct).
J'ai essayé de regarder, mais je ne trouve pas le problème. Si quelqu'un peut y jeter un oeil et me donner l'explication, je suis preneur.
Merci, --Jim Bey (d) 24 juillet 2020 à 08:46 (UTC)Répondre
- Ces parties sont-elles particulièrement volumineuses ? Est-ce que les dernières notes fonctionnent mais pas les premières ? Si la réponse est oui aux deux, c'est la faute du générateur de livre numérique, qui fabrique des sections quand la taille maximum d'un chapitre est atteinte. Comme les liens texte-note ne fonctionnent qu'à l'intérieur d'un "chapitre", seule la dernière section, qui contient les notes, a un fonctionnement correct. On peut repérer le changement de section à un haut de page sans raison. Voir La France juive, livre bavard, où j'avais introduit des sous-chapitres pour remédier. --Wuyouyuan (d) 24 juillet 2020 à 10:37 (UTC)Répondre
- Jim Bey :À voir le livre dont les parties sont effectivement très longues (ie la 5e partie fait 363 pages), c’est bien le cas décrit par Wuyouyuan j’ai déjà rencontré ce problème et l’ai fait remonter dans le cadre des demandes d’amélioration par Wikimédia/Métawiki en mai dernier, elle est en cours de traitement si c’est possible. Le lien vers la demande est ici. L’échange dans mon exécrable anglais ne facilite pas les choses .--Cunegonde1 (d) 24 juillet 2020 à 11:48 (UTC)Répondre
- Collègues, Le créateur de livres fonctionne mal si le volume de texte est grand et si le nombre de notes est grand. Si la taille du texte excède 250 ko et que l'on demande un ePub, WsExport divise le texte en plusieurs blocs et, à ce moment, les liens vers les notes ou à partir des notes sont régulièrement brisés. La correction est facile : il faut indiquer à WsExport de ne pas diviser en blocs les fichiers ePub (j'ai installé Calibre sur mon ordinateur et c'est comme ça que j'ai réglé ce problème). Si le nombre de notes excède 99, le créateur de livres déraille. Ce problème est selon mon expérience de développeur facile à corriger, mais il revient aux développeurs du logiciel Calibre de le faire. Pour ma part, j'ai développé une façon de contourner le problème, toujours sur mon ordinateur. Si j'étais moins occupé dans l'IRL et plus préoccupé par WS, j'aurais déjà créé un second WsExport qui corrige ces deux bogues. Désolé, — Cantons-de-l'Est discuter 24 juillet 2020 à 12:21 (UTC)Répondre
- Cantons-de-l'Est : indiquer à WsExport de ne pas diviser en blocs les fichiers ePub. Quel est le truc ? Je 'ai pas trouvé de paramètre dans l'appel de Wsexport ( https://wsexport.wmflabs.org/tool/book.php ). J'ai Calibre sur mon ordinateur. Aussi bien, il y a une limite à cette cuisine: les possibilités des liseuses d'avaler de gros blocs. Les bons éditeurs ont semble-t-il résolu le problème avec un lien interne note-texte qui survole le bloc, permettant de faire des livres avec les notes en fin de volume. --Wuyouyuan (d) 24 juillet 2020 à 12:48 (UTC)Répondre
- Wuyouyuan, Ce paramètre est disponible dans Calibre, mais l'interface de WsExport ne permet pas de le modifier. — Cantons-de-l'Est discuter 25 juillet 2020 à 13:31 (UTC)Répondre
- On peut modifier la division en blocs dans Calibre, mais encore faut-il pouvoir disposer d'un format d'origine sain. Or, d'après mes test sur Les Mystères de Paris/Partie IV, quel que soit le format d'export (pdf, epub, mobi), on constate que les liens 1 à 6 ne fonctionnent pas (les notes renvoient toujours sur la page 146 ?), les notes 7, 8, 9 sont seules correctes. --Jim Bey (d) 25 juillet 2020 à 15:04 (UTC)Répondre
- Jim Bey, C'est la première fois que j'observe ce type de problème. Je vais creuser pour tenter de le résoudre. — Cantons-de-l'Est discuter 25 juillet 2020 à 23:35 (UTC)Répondre
┌─────────────────────────────────────────────────┘
Jim Bey, J'ai exporté, au format PDF, les parties de l'ouvrage qui comprennent des notes. Le bilan est plutôt triste :
- Partie I : OK pour les liens
- Partie II : OK pour les liens
- Partie III : OK pour les liens
- Partie IV : non
- Partie V : OK pour les liens
- Partie VI : non
- Partie VII : non
- Partie VIII : non
- Partie IX : non
- Partie X : OK pour les liens
- Notes : non (même si deux liens seulement)
J'ai essayé des trucs pour la partie IV, mais la navigation par liens est encore en erreur pour le format PDF. Par le nombre d'octets et le nombre de liens, la partie I est plus lourde que la partie IV. Pourtant, la navigation par liens dans la Partie I me semble correcte pour tous les liens. Si d'autres idées viennent à mon attention, j'essaierai de creuser.
— Cantons-de-l'Est discuter 26 juillet 2020 à 13:28 (UTC)Répondre
- Cantons-de-l'Est, c'est ce que j'avais en gros constaté. J'ai d'abord pensé que c'était dû à des notes trop longues (> 1k) (mais ça ne vaut pas pour la VII et les notes). Et le problème est reproductible avec tout livre contenant un certain volume de notes. --Jim Bey (d) 26 juillet 2020 à 17:02 (UTC)Répondre
- Cantons-de-l'Est : et autres. Comme vous l’avez sûrement remarqué, Ws-Export redéfinit tous les ancres ou identifiants ainsi que les classes CSS afin de s’y retrouver plus facilement. J’ai exploré rapidement la partie IV de cet ouvrage identifiée comme étant à problème. Dans le traitement de cette page, Ws-Export aurait dû attribuer les ancres comme suit:
- calibre_link-0 : page frontispice
- calibre_link-1 : Titre de l’ouvrage
- calibre_link-2 à calibre_link-10 : Notes de bas de pages reportées à la fin
- calibre_link-11 à calibre_link-19 : Ancres dans le corps du document à l’endroit où on réfère aux notes 2 à 10 à la fin du document
- Curieusement l’ancre calibre_link-8 se retrouve en page 201 au lieu d’encadrer la note 7. Autre curiosité: il n’y a même pas de note de bas de page à la page 201. C’est sans doute à ce moment que Ws-Export a perdu le compte et réattribué de faux identifiants aux notes 1 à 6. Les notes 7, 8, 9, quant à elles, fonctionnent mais on remarque un décalage de numéro (9 à 11 au lieu de 8 à 10).
- Que s’est-il produit en page 201 pour que Ws-Export y insère (à l’endroit où « Monsieur — dit tout bas ») une ancre destinée à la note 7 ? Et bien ! je tente une explication : à partir du navigateur Chrome, on peut inspecter le code source html en tout point d’un document. Ce faisant, on retrouve (à la page 201) la liste complète des notes de bas de page alors que nous avons à peine franchi la moitié du document. Coïncidence ! Mais que voit-on au-dessus de cette liste ? Un encadré qui nous informe que si on veut faire afficher les nœuds intermédiaires, il faut appuyer sur le lien « Show All Nodes (1063 More) ». Voilà sans doute le nœud du problème rencontré par Ws-Export. Par curiosité : pourquoi des documents aussi volumineux ? N-B: j’ai utilisé l’exportation en htmlz donc sans fractionnement des fichiers. --Denis Gagne52 (d) 27 juillet 2020 à 17:36 (UTC)Répondre
- Cantons-de-l'Est : Wuyouyuan : - Quelques réflexion peut-être idiotes : en parcourant un certain nombre d'ebooks contenant des notes,
je constate qu'elles apparaissent en fin de chaque chapitre (délimités par des balises h2 ou h3 - le découpage xhtml est fait par chapitre), or dans les Mystères de Paris, elles se retrouvent toutes en fin de volume (il n'y a pas de balises h pour les titres, et le découpage xhtml est fait selon le volume <260k). Cela peut-il être dû à l'utilisation de "==" pour les intertitre au lieu de "t3" ? --Jim Bey (d) 30 juillet 2020 à 15:04 (UTC) [Correction : C'était bien idiot : j'ai comparé avec des volumes découpés par chapitre, ce qui n'est pas le cas ici !]--Jim Bey (d) 1 août 2020 à 12:55 (UTC)Répondre
- Jim Bey, Il n'y a aucun
== dans la partie IV, à la suite de modifications que j'ai faites plus tôt cette semaine. Néanmoins, votre relance m'a donné des idées. Dans la Partie IV, j'ai supprimé des trucs superflus et j'ai ajouté des sauts de page avant les chapitres pour rendre la lecture plus agréable. Toutefois, je n'ai pas résolu le problème de navigation des notes (seule la note [9] fonctionne correctement). — Cantons-de-l'Est discuter 30 juillet 2020 à 23:24 (UTC)Répondre
- Jim Bey, J'ai regroupé les notes par chapitre, plutôt que pour toute la partie IV. Dans le fichier PDF, la navigation par liens fonctionne correctement. Faites des essais et dites-moi si les exports de la partie IV vous plaisent. Si oui, on pourra probablement rendre rectifier les autres parties. — Cantons-de-l'Est discuter 31 juillet 2020 à 12:04 (UTC)Répondre
- Cantons-de-l'Est, oui, cela fonctionne, mais, pardon de ma brutalité, si c'est ingénieux, cela relève du bricolage ; l'objectif n'est pas tant que cela me plaise (j'avais déjà corrigé l'ebook localement dans Calibre pour le lire), que de comprendre pourquoi on n'arrive pas à l'exporter correctement, et pourquoi sa structure diffère d'autres du même type. --Jim Bey (d) 31 juillet 2020 à 13:48 (UTC)Répondre
- Jim Bey, Bricolage, oui et non. Merci pour ingénieux. Nous ne contrôlons pas Calibre, hélas ! Avant de trouver une solution, j'ai modifié les pages de plusieurs façons, toutes correctes, souhaitant que WsExport parvienne à créer un export viable. Selon mon analyse, le bogue se trouve quelque part dans les 390 pages de la partie IV, et non pas dans les 200 premières pages. Je crois qu'il s'agit d'un caractère de contrôle intempestif mais il est invisible aux yeux humains. Mon temps bénévole étant fini, je ne chercherai pas plus longtemps un autre correctif. Comme alternative valide, vous pouvez remplacer
<ref>...</ref>...<references/> par {{refa}} et {{refl}}, mais l'effort est plus grand. En terminant, si vous appliquez aux autres parties fautives la recette que j'ai mise au point, les internautes pourront aisément consulter les notes de toutes les parties des Mystères de Paris. — Cantons-de-l'Est discuter 31 juillet 2020 à 14:23 (UTC)Répondre
- Cantons-de-l'Est : Finalement, je vais me convertir au "bricolage" (car l'autre option serait de redécouper le volume en chapitres). Il suffit simplement d'ajouter <références/> en dernière page de chapitre (par défaut en pied de page et en noinclude), ce qui évite d'avoir à recalculer toute la pagination. --Jim Bey (d) 1 août 2020 à 16:02 (UTC)Répondre
Le prénom de l'héroïne est « Elys ». J'ignore s'il s'agit d'un E ou d'un É. J'ai commencé récemment, et je viens seulement de me dire que ce prénom avait peut-être la même racine de Élysée. C'est un peu tard, mais je suis prête à ajouter un accent aigu là où je ne l'ai pas fait initialement. Tipram (d) 26 juillet 2020 à 09:40 (UTC)Répondre
- Bonjour @Tipram. Je n'ai pas une référence qui appuie mon propos, mais j'ai remarqué que si e est en première position et forme une syllabe à lui seul, il est accentué (c.-à-d. é-lé-phant, mais el-fe). Suivant cela, Élys est normalement accentué. En pratique, de nombreux typographes ont fait et font toujours l'économie des lettres majuscules accentués, bien que l'Académie française en recommande l'usage. C'est donc à vous et aux autres contributeurs de ce livre de s'accorder sur l'accentuation automatique des majuscules (ce qui est l'usage majoritaire sur Wikisource et celui recommandé par l'AF) ou non (meilleur respect du FS au détriment de l'orthographe). --Jahl de Vautban (d) 26 juillet 2020 à 10:50 (UTC)Répondre
- Merci, Jahl de Vautban. Je vais donc ajouter l'accent aigu sur l'initiale de ce prénom. Bonne continuation. Cordialement, Tipram (d) 26 juillet 2020 à 11:15 (UTC)Répondre
Bonjour,
dans la page Spécial:Doubles redirections pour Dictionnaire critique de la langue française/Epitre, il y a deux redirections et je ne sais pas où se trouve le texte original, un admin peut-il supprimer ce qui ne va pas.
Merci
--Le ciel est par dessus le toit Parloir 29 juillet 2020 à 16:01 (UTC)Répondre
- Bonjour @Le ciel est par dessus le toit. En regardant l'historique, on voit qu'à l'origine étaient transcluses les pages 3 à 5 de ce livre, puis de ce livre. Or, quand on regarde les pages liées aux pages concernées, on s'aperçoit qu'elles ne sont plus transcluses nulle part. Comme je ne vois pas bien ce qui peut justifier une redirection (à moins de rediriger vers Dictionnaire critique de la langue française/Épître, avec un e accent aigu et un i circonflexe, qui est l'orthographe correcte de ce mot), je serais tenté d'annuler la dernière diff sur cette page et du même coup la redirection. --Jahl de Vautban (d) 30 juillet 2020 à 06:16 (UTC)Répondre
- Habituellement le champ « série » sert à définir une clé commune à plusieurs ouvrages de façon à permettre leur regroupement suivant un ordre logique.
- Il en est ainsi dans Wikidata. Par exemple, Le Lion, la Sorcière blanche et l'Armoire magique occupe le premier rang de la série « Le monde de Narnia » (P179).
- Calibre lui attribue plutôt le contenu « Le monde de Narnia [1] ».
- C’est à partir de cette information que Kobo réussit à trier ses epubs par ordre de série.
- La structure d’un fichier epub prévoit un fractionnement en chapitres qui prennent la forme de fichiers distincts. Chaque chapitre possède alors ses propres identifiants. Par contre, les éléments différents d’une même « série » ne cohabitent pas normalement à l’intérieur d’un fichier epub à moins de les déguiser en chapitres ce qui n’est pas fait actuellement.
- Dans l’état actuel de Ws, je vois difficilement comment on pourrait partager la notion de « série » avec le monde extérieur.
- Regrouper des livres d’une même série à l’intérieur d’un fichier epub n’est définitivement pas une solution à recommander.
- N’y aurait-il pas lieu de s’harmoniser avec le monde extérieur et de créer des séries facilement exportables ? --Denis Gagne52 (d) 30 juillet 2020 à 01:09 (UTC)Répondre
- Bonjour Denis Gagne52 :,
- Oui, je suis complètement pour l'idée se faciliter l’export de nos ouvrages.
- Par contre, je ne suis pas sûr de ce que tu dis ni de ce que tu veux faire. Serait-ce juste ajouter un ou des champs dans la structure des index ?
- Cdlt, VIGNERON (d) 30 juillet 2020 à 07:44 (UTC)Répondre
- Bonjour VIGNERON :, le champ « Série » existe déjà dans l’index mais Ws nous invite à l’utiliser autrement. Exemple : Livre:Sue - Les mystères de Paris, 1ère série, 1842.djvu. Si on maintient le statu-quo, comment pourrons-nous faire savoir à Calibre que « Le Lion, la Sorcière blanche et l'Armoire magique » est le premier livre de la série « Le monde de Narnia ». Pour ce faire, il faudrait plutôt inscrire dans le champ Série de l’index la valeur suivante : « Le monde de Narnia [1] » et non des liens à tous les autres livres de la série.
- Tant et aussi longtemps qu’on demeure dans Ws, la présentation de la série « Les mystères de Paris » est impeccable. Cette série est d’autant plus intéressante qu’elle permet de découvrir quelques pièges qui nous guettent en exportation, par exemple :
- Fichier epub sans table des matières composé d’un index html trop lourd si les chapitres ne sont pas définis dans le sommaire avec sous-page associée ;
- liens rompus lorsque les serveurs n’arrivent pas à fournir à Calibre toute l’information requise pour la reconstruction du html en vue d’un découpage en fichiers plus petits ;
- 10 livres porteront le même titre : « Les mystères de Paris » une fois exportés dans Calibre…
- Utilisateur:Wuyouyuan a réussi à contourner plusieurs de ces problèmes en créant un sommaire regroupé pour les deux Tomes de La France Juive mais la solution classique demeure d’exploiter le champ Série pour ce à quoi il est normalement destiné, soit établir un lien entre les différents livres d’une même série. --Denis Gagne52 (d) 30 juillet 2020 à 15:27 (UTC)Répondre
- La France juive a très banalement réduit les deux tomes à un seul ouvrage en définissant un sommaire complet dans la page principale (nombreux exemples, Les Papiers posthumes du Pickwick Club et d'autres). Pour voir plus beau, contempler Mémoires (Saint-Simon) (pas de "bon pour export" parce que les pages sont roses) qui permet de créer un livre numérique des 20 tomes, avec même un sommaire généré à deux niveaux. La même recette peut être appliquée à une "série", en empilant les volumes dont le titre est différent. Cela obligera peut-être à créer, dans l'esprit de [...]/Texte entier, des [...]/Liseuse , j'en ai défini un pour Le Monde comme volonté et comme représentation (encore en chantier) pour gérer la structure proliférante de l'ouvrage. --Wuyouyuan (d) 30 juillet 2020 à 17:52 (UTC)Répondre
- Si je peux me permettre d’exprimer une préférence, elle irait à Mémoires (Saint-Simon) qui offre la possibilité d’exporter en respectant le découpage original. J’ai noté toutefois que , lors de l’exportation, ws-export attribue le même titre à tous les tomes. Cela n’en demeure pas moins un exemple duquel on aurait avantage à s’inspirer.
- J'avais sacrifié la distinction des volumes en livre numérique à la cohérence de la navigation en ligne ; il y a un remède, que j'appliquerai un jour.--Wuyouyuan (d) 3 août 2020 à 09:25 (UTC)Répondre
- Celui qui a créé l'ouvrage en 2006 l'a appelé ainsi, contrairement à la page de titre, et cela fut respecté depuis. Pourquoi le père fondateur Utilisateur:ThomasV fit-il ainsi, contrairement à ses principes, il faudrait le lui demander. Peut-être parce que c'est la traduction littérale du titre anglais The Posthumous Papers of the Pickwick Club. --Wuyouyuan (d) 3 août 2020 à 09:25 (UTC)Répondre
Je viens d’achever à l’instant la correction des Recherches sur le refroidissement des planètes au sommaire de l’Histoire naturelle de Buffon, et je me rends compte que la transclusion échoue avant la fin du mémoire. Il me semble qu’un problème analogue avait affecté la correspondance de Voltaire il y a quelques semaines. Ici, les quarante dernières pages environ ne sont pas transcluses, et les modèles utilisés dans les notes ne sont pas appliqués. Je pense que cela provient d’une « surcharge » en modèles : c’est un très long article sans subdivision, qui abonde en fractions et en valeurs numériques, si bien qu’il y a des centaines d’occurrences de {{sfrac}} et {{unité}}, avec en plus des {{nobr}} pour éviter des coupures de lignes. Que puis-je faire pour y remédier ? — ElioPrrl (d) 31 juillet 2020 à 18:18 (UTC)Répondre
- Bonjour @ElioPrrl. Il est sans doute possible de diminuer le nombre des modèles en gérant les fractions via les balises math. Ainsi, 14440 11/30/361/2873020 1/6 deviendrait
 . C'est moins joli
. C'est moins joli et ça ne permet pas la recherche en plein texte (en fait si, mais ça ne surligne pas le texte, en tout cas chez moi) (et j'ignore comment cela réagit avec le modèle corr), mais ça peut être une piste à explorer. --Jahl de Vautban (d) 31 juillet 2020 à 19:40 (UTC)Répondre
- Je suis d'accord, il faudrait utiliser la balise math plutôt que le modèle
{{Sfrac}} (et pas juste quand il y a surcharge des modèles d'ailleurs). Cdlt, VIGNERON (d) 1 août 2020 à 13:55 (UTC)Répondre
- Jahl de Vautban et VIGNERON : Je veux bien, mais ce sera au prochain relecteur alors ! (le travail a été tellement rebutant que je n’ai pas le courage de le refaire ) Pourquoi d’ailleurs cette préférence ? A-t-on comparé les poids de chacune des solutions ? J’ai utilisé
{{sfrac}} non seulement parce qu’il utilise la police ambiante et permet d’y inclure d’autres modèles (dont {{corr}}), mais aussi parce qu’elle ne nécessite ni la génération d’une image SVG, ni l’interprétation par MathJax ; le contenu mathématique se résumant à des fractions, je pensai que c’était la solution la plus esthétique et, en tant que pur CSS, la plus compatible avec tous les dispositifs de lecture.
- En attendant, j’aurais plutôt divisé le mémoire en trois parties : refroidissement des planètes, refroidissement de leurs satellites, conclusions. Comme je doute que personne lise jamais ce mémoire en entier, cela aurait au moins eu le mérite de faciliter la navigation au lecteur, pressé de passer tous ces calculs indigestes et périmés pour aller directement aux conclusions que Buffon tire sur la possibilité de la vie sur les planètes. — ElioPrrl (d) 1 août 2020 à 17:39 (UTC)Répondre
- Compte tenu de la faible probabilité pour que quelqu’un se lance rapidement dans un chantier de conversion du modèle vers les balises math (une conversion automatique par script semble possible, mais pas forcément souhaitable pour les raisons que tu donnes), la division en plusieurs transclusions est sans doute la meilleure solution en effet.
- Peut-être aussi pourrait-on réduire la charge en modèles de
{{sfrac}} en faisant des versions {{sfrac1}}, {{sfrac2}} et {{sfrac3}} selon le nombre de paramètres, afin d'éviter les tests internes ? Seudo (d) 2 août 2020 à 09:04 (UTC)Répondre
Le fichier semble disparu, quelqu’un peut essayer de le retrouver. Merci. --Le ciel est par dessus le toit Parloir 1 août 2020 à 10:20 (UTC)Répondre
- Le ciel est par dessus le toit : il a été supprimé sur Commons le 26 juillet, au motif qu'aucune licence n'était indiquée. --Jahl de Vautban (d) 1 août 2020 à 11:08 (UTC)Répondre
- Jahl de Vautban : Déjà je ne parle pas anglais, d’autre part je n’y connais rien en licence, donc si quelqu’un peut se charger de faire une demande de restauration avec les élément demandé, je l’en remercierai vivement. Ce qui est étrange c’est que seul ce numéro de la série, il me semble à été supprimé --Le ciel est par dessus le toit Parloir 1 août 2020 à 12:05 (UTC)Répondre
- Le ciel est par dessus le toit : si j'ai bien compris, tous les numéros suivants sont hébergés ici sans passer par Commons : comme ils sont publiés en 1925 et après, ils ne sont pas DP-US et ne sont pas admissibles sur cette plateforme. A l'inverse, tous les précédents, publiés en 1924 et avant, le sont et sont donc hébergés sur Commons. Il semble que ce numéro ait été mis par inadvertance sur Commons, et c'est ce qui a entraîné sa suppression. Si on veut le réuploader, il faudra le faire en local. Comme je ne pense pas qu'on puisse le restaurer même temporairement, ça veut probablement dire qu'il faut télécharger le fichier sur Gallica et récréer le DJVU. --Jahl de Vautban (d) 1 août 2020 à 12:42 (UTC)Répondre
- Jahl de Vautban et Ernest-Mtl : Merci pour les explication, je ping Ernest pour l’import s’il a un un peu de temps --Le ciel est par dessus le toit Parloir 1 août 2020 à 13:15 (UTC)Répondre
- Mhh, le fichier était à l'origine en local sur Wikisource, je l'y ai donc restauré localement en attendant de savoir quoi et comment faire sur Commons (ceci dit, j'aurais aussi pu restaurer temporairement pour récupérer le fichier sur Commons si besoin).
- Ceci dit, j’émets de très forts doutes sur les droits d'auteurs ; il faudrait vérifier pour chacun des auteurs de chacun des tomes si leurs textes peuvent effectivement être retranscrits sur Wikisource, il est quasiment impossible que tout ces auteurs soit tous morts avant 1949. Et en attendant, je déconseille de retranscrire les textes sans avoir fait cette vérification de base.
- Cdlt, VIGNERON (d) 1 août 2020 à 14:05 (UTC)Répondre
- VIGNERON : Merci --Le ciel est par dessus le toit Parloir 2 août 2020 à 08:11 (UTC)Répondre
